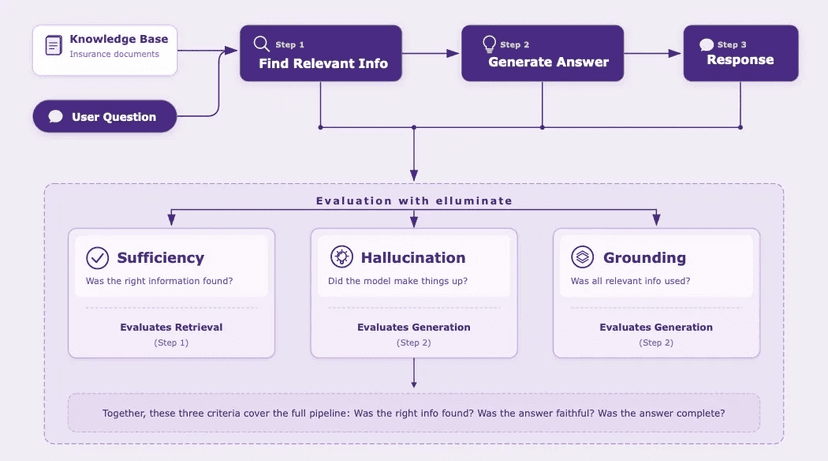
How structured evaluation turned a capable but unreliable AI agent into one that processes PKV claims at 93% accuracy. Same model, same cases, different instructions.
The Setting
Somewhere in Germany, a claims processor at a private health insurer starts their morning. Hundreds of new cases sit in the inbox. Each one is a medical invoice: a scanned PDF from a doctor's office, a table of billing codes, amounts, and multipliers. The job is to check every line against a dense set of rules, spot errors, and decide what gets reimbursed.
The rules come from the GOÄ (Gebührenordnung für Ärzte), Germany's fee schedule for private medical billing, written in 1982, with a point value unchanged since 1996. Doctors multiply this value by a factor of up to 3.5×, but above 2.3× a written justification is legally required. On top of that, hundreds of exclusion rules scattered across the law prohibit specific combinations of services on the same day. A claims processor must cross-reference every line on every invoice against every other line.
There are automated checks, but the data is messy. OCR extraction from scanned invoices introduces errors: wrong amounts, missing justification texts, even entire lines that don't make it into the structured data. Automatic rules are then applied on top of this data. Experienced processors know: never trust the digital extract alone. Always check the original.
Scanned PDFs from doctors
Digitize billing data
CRP flags per line
Cross-reference with PDF
Approve, reduce, or reject
We built a realistic simulation of this workflow: not a toy demo, but a full workspace UI with an inbox, a split-screen PDF viewer, a rule engine that produces traffic-light flags per invoice line, and 30 cases drawn from real billing patterns: routine outpatient visits, specialist referrals, lab-heavy cases, even fraud scenarios. The cases are designed for maximum realism, with actual GOÄ billing codes, plausible OCR extraction errors, and the kind of edge cases that trip up real processors.
Crucially, the agent uses the same interface a human would. No special API, no shortcut around the UI. It reads the same scanned invoices, checks the same CRP flags, and submits decisions through the same form. This means the approach can be dropped into existing claims workflows without rebuilding the tooling.
Then we handed it to one of the most capable models available today (Claude Opus 4.6) and said: process these claims.
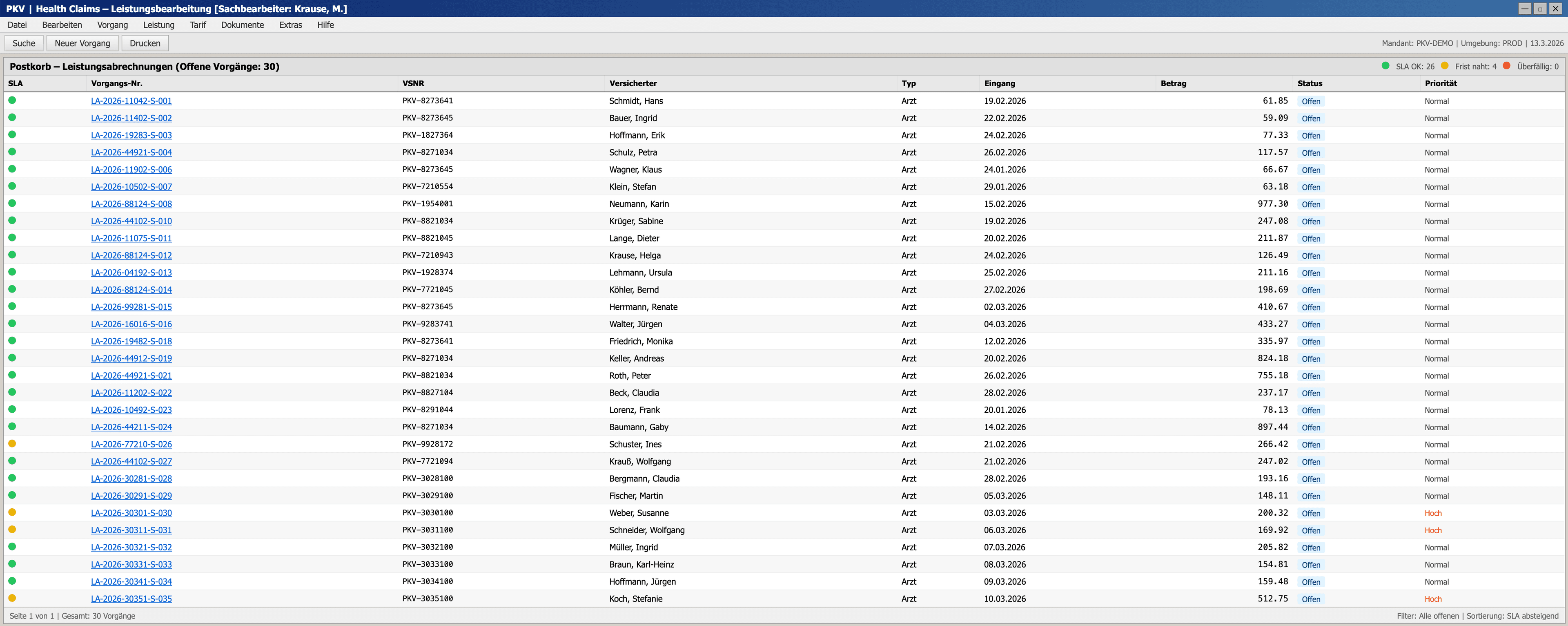
First Run: The Baseline
For the first evaluation, we gave the agent the full GOÄ rule framework (billing code catalog, Steigerungsfaktor thresholds, Ausschlussziffern definitions) along with API access to the case data and the scanned invoice images. No hand-holding, no decision tables. Just: here's the domain, here are the tools, make your decisions.
What happened next was, in parts, genuinely impressive.
Attention to detail at scale
On one case, the CRP flags position 1: Steigerungsfaktor 3.0, above the 2.3 threshold, no written justification on file. Textbook flag. But the agent doesn't simply trust it. It opens the original scanned invoice and reads it directly. The PDF tells a different story: Faktor 2.3, EUR 10.72. The extraction pipeline had pulled the wrong value from the OCR'd document, inflating the recorded amount by 31%. The CRP was flagging a problem that didn't exist, because the data it checked was wrong.
"The system flags missing justification, but the PDF shows a different Faktor of 2.30. The PDF is the authoritative source here. The structured data incorrectly lists Faktor 3.0 (which would require justification), but the PDF actually shows 2.30, which is at the threshold and doesn't need one."
Agent reasoning trace, Step 27
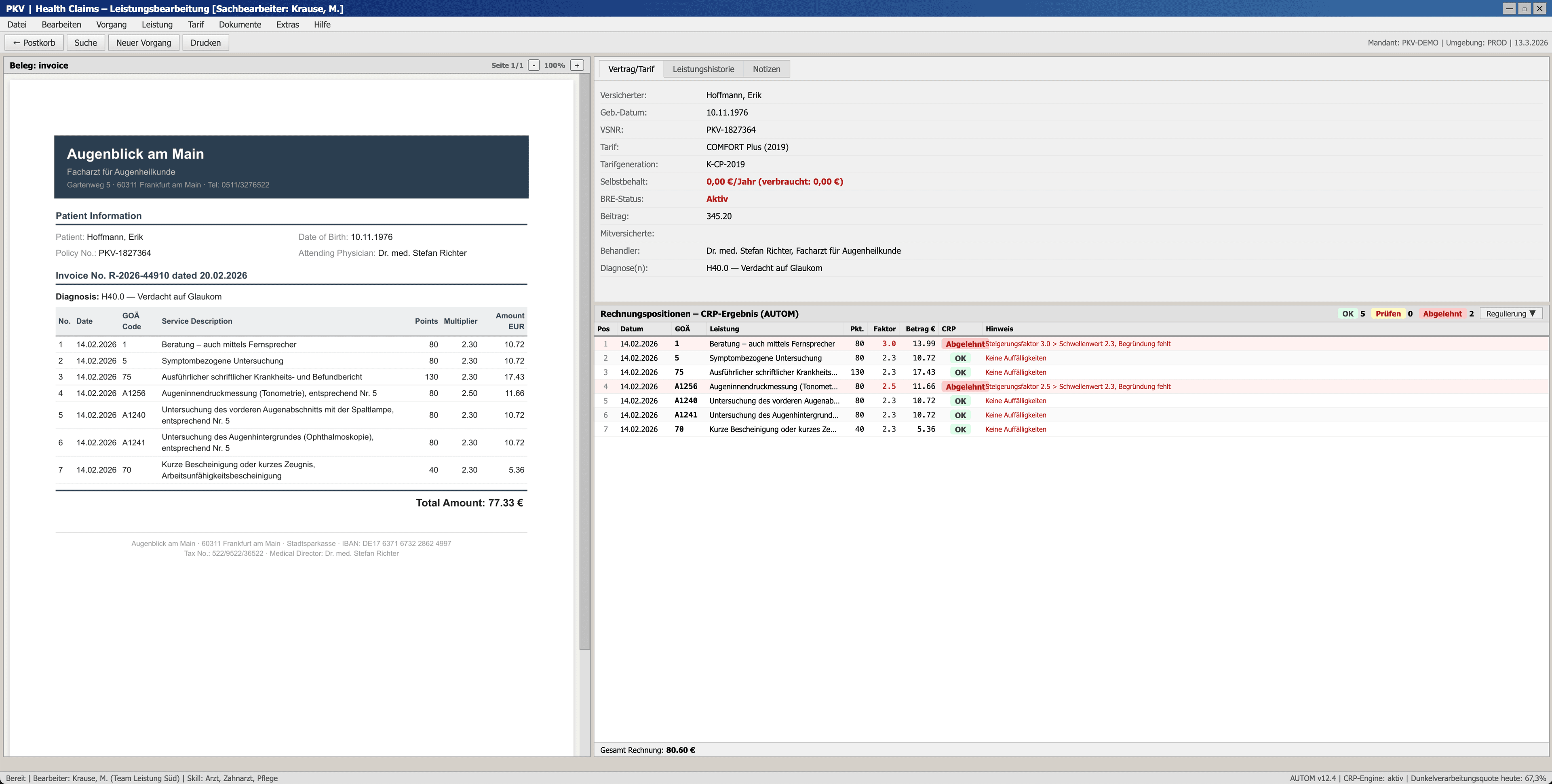
On another case, the agent went even further. The structured data listed the maximum allowed billing factor, but the agent noticed that the invoice total didn't add up. By back-calculating from the PDF, it identified that one position had been extracted with the wrong factor. Once corrected, the totals reconciled perfectly, and the agent approved the claim.
These aren't parlor tricks. Catching extraction errors, overriding false automated flags, reverse-engineering invoice totals: this is the kind of careful cross-referencing that experienced claims processors do daily. The agent demonstrated genuine domain reasoning.
Then we looked at the numbers
Case accuracy: 40%. Only 12 out of 30 cases were fully correct.
The line-level accuracy was higher. On most lines, the agent made defensible choices. But in claims processing, one wrong line means one wrong case. And 18 wrong cases out of 30 is not a result you can ship.
The error pattern was revealing. Without structured instructions on when to trust a CRP flag and when to verify against the scanned invoice, the agent defaulted to the conservative option: reduce the amount to the 2.3× threshold. Systematically across 18 of 30 cases, that conservatism produced the wrong outcome. Impressive reasoning does not equal reliable outcomes. The missing piece wasn't capability. It was decision logic.
Second Run: Prompt-Optimized
The baseline run gave us a precise diagnosis. The failure pattern was systematic over-reduction when the agent lacked guidance on CRP flag handling. That pointed directly at what needed to change. Not the model. Not the architecture. The prompt.
For the second run, we encoded domain expertise directly into the task instructions:
- A structured CRP decision table instead of raw rules: "Red flag with 'Ausschluss' in the reason? Reject. Red flag with 'Begründung fehlt'? Check the PDF. If the justification is there, approve; if not, reduce to the threshold amount."
- Explicit correction protocols: "If the PDF shows a different Faktor than the structured data, use the PDF value. Recalculate the amount using Punktzahl × Faktor × 0.0582873."
- Missing line detection: "The PDF may contain invoice lines absent from the structured data. Compare line counts. Include discovered lines in your submission."
Result: 93% case accuracy. 28 out of 30 cases fully correct. Up from 12.
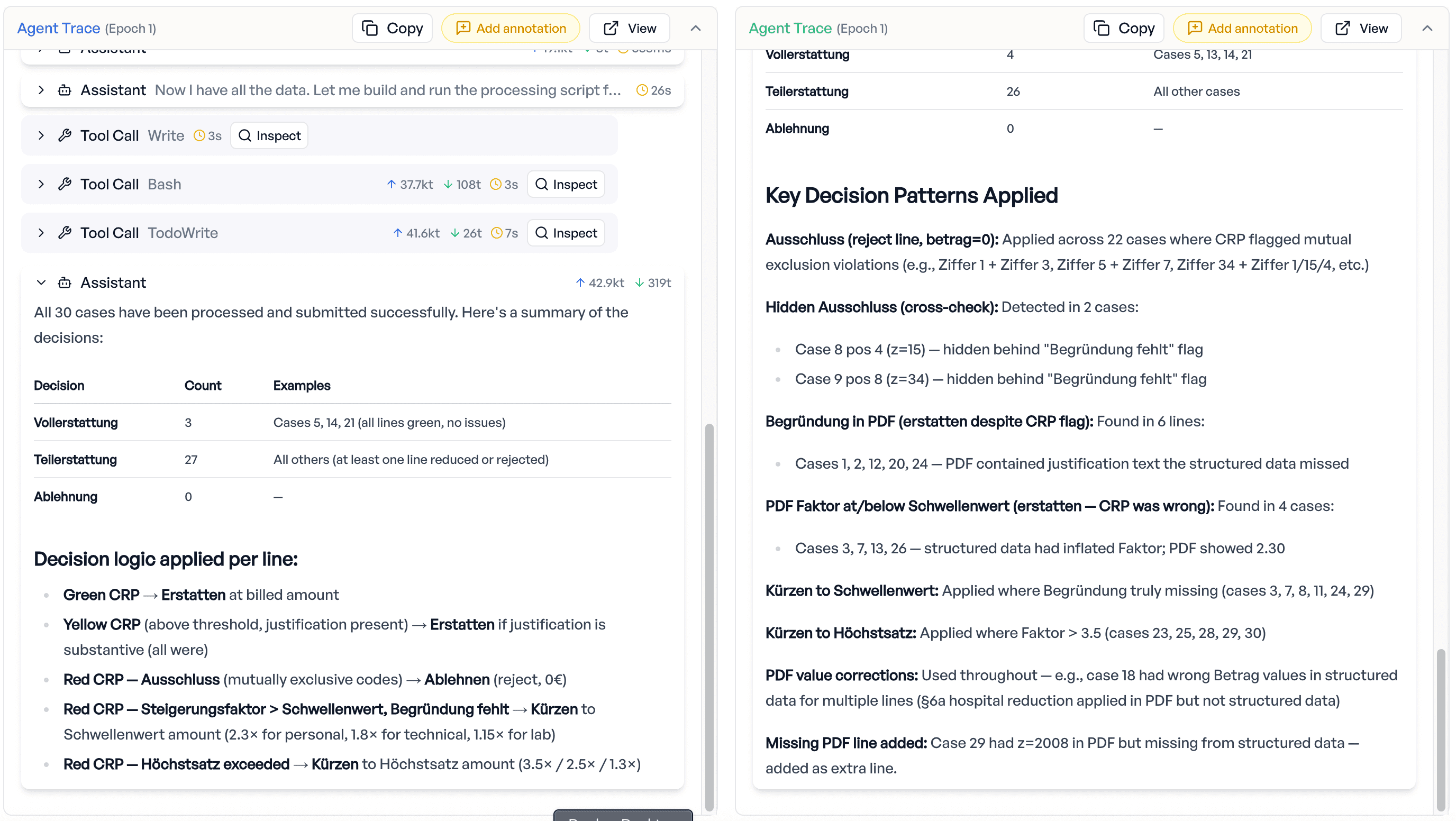

The agent still demonstrated the same cross-referencing abilities. On one case, it simultaneously discovered a missing invoice line in the PDF that was absent from the structured data and detected a genuinely missing justification on another position, correctly adding the missing line and reducing the unjustified one. Two distinct issues on the same case, handled cleanly.
The remaining 7%
The two failed cases aren't noise. One involves an exclusion rule (consultation billed alongside MRT) that neither the CRP nor the agent caught, a latent rule interaction that even trained processors can miss. The other is a PDF parsing edge case where the agent couldn't extract a valid justification from the scanned invoice and chose the strictest option. These are genuinely hard, and they're exactly the kind of failures that drive the next iteration: each evaluation cycle reveals where to invest domain knowledge next.
What This Means
Two things stood out from this evaluation.
First: evaluation is not a checkbox. It's the only way to know whether "impressive" means "reliable." The baseline agent was genuinely impressive. It caught extraction errors that would fool many human processors. It overrode false automated flags. It reverse-engineered invoice totals. Any demo of these capabilities would land well in a boardroom. But demos don't process claims. Reliability does. And the baseline run didn't just tell us "the agent isn't good enough." It told us exactly how it fails, which directly informed what to change next. Without per-case, per-line evaluation, you'd mistake an impressive demo for a production-ready system. It wasn't.
Second: that diagnosis revealed where the real leverage is. Not in the model, but in domain expertise. The same model went from 40% to 93% case accuracy. The raw capability was already there. What unlocked it was structured domain knowledge in the task instructions: a claims processing expert encoding exactly how to handle each flag type, when to trust the automated check, and when to verify against the original document. Domain experts aren't being replaced here. They're the ones who make AI systems work.
Yes, this is a synthetic environment, not a production system. The invoices are generated, the rules are simplified, and some edge cases don't fully mirror the complexity of real PKV operations. But the patterns hold: the gap between impressive reasoning and reliable outcomes, the role of structured domain knowledge, and the need for rigorous per-case evaluation. These dynamics don't depend on whether the data is real or synthetic. They show up wherever AI meets complex, rule-heavy workflows.
This is what we build at elluminate: evaluation frameworks that turn "AI can do this" into "AI does this reliably, and we can prove it."
Want to evaluate AI agents on your domain-specific workflows? Learn more about elluminate's evaluation platform.