A framework for systematic RAG evaluation -- from test design to production monitoring.
A health insurance chatbot tells a customer that cosmetic surgery isn't covered. The customer accepts this and moves on. But the insurer does cover certain cosmetic procedures -- the relevant policy document just wasn't in the chatbot's retrieval index. No hallucination. No obvious error. Just a quiet, confident wrong answer that looks exactly like a correct one.
This is the core challenge of RAG evaluation: the failures that matter most are often invisible in the output. The system retrieved documents, the LLM generated a reasonable-sounding response, and everyone moved on -- except the answer was wrong. How do you catch this before your users do? That's what this post is about.
We walk through a complete evaluation workflow using a case study: a RAG-powered chatbot for an imaginary German health insurer Sehr Gute Krankenkasse (SGKK) that answers member questions about coverage, co-payments, and benefits. The approach covers test set design, targeted evaluation criteria, experiment analysis, and continuous production monitoring.
The Evaluation Framework
Structuring the Test Set
A well-structured test set is the foundation of RAG evaluation. Rather than throwing random questions at the system, we designed a test set with two classification axes that enable targeted analysis later:
Axis 1: Difficulty
- Easy -- Direct answers from a single document. "What does SGKK cover for dental prosthetics?"
- Medium -- Requires understanding context and combining information. "How much is the sick pay for employees?"
- Hard -- Requires multi-document synthesis or covers complex topics. "What are the advantages of SGKK compared to other insurers?"
- Unanswerable -- Questions the system should not be able to answer, either because they're outside the knowledge base or outside the domain entirely.
Axis 2: Topic
- Insurance related -- Legitimate health insurance questions, including some not covered in the knowledge base ("Does SGKK cover LASIK eye surgery?").
- Not insurance related -- Questions completely outside the domain ("What's the weather tomorrow?", "Can you give me a lasagna recipe?").
This two-axis categorization pays off when analyzing results. Instead of staring at a single aggregate score, you can filter the data to understand where and why your system fails -- and whether those failures actually matter.
Beyond the static test set, we also set up daily production monitoring: each day, a batch of real user queries is evaluated using the same criteria, catching regressions before they affect a significant number of users.
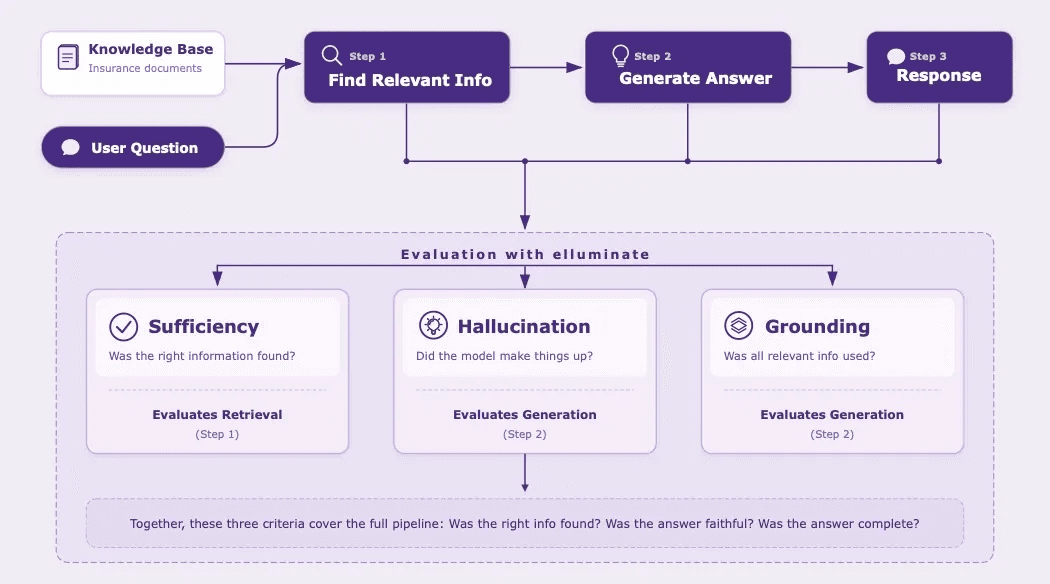
Evaluation Criteria
Not every RAG failure is the same. A system that invents information is worse than one that simply doesn't find the right document. To capture these distinctions, we defined three targeted evaluation criteria:
Sufficiency -- Is the information in the retrieved chunks enough to answer the given query?

This criterion evaluates the retrieval component in isolation. It ignores the LLM's response entirely and focuses only on whether the retrieved chunks contain the information needed to answer the question. If Sufficiency fails, the retrieval pipeline didn't find the right documents -- regardless of what the LLM did with the context.
Hallucination -- Is the answer free from hallucination? Compare it with the information in the given context.

This criterion checks whether the LLM stayed faithful to the provided context. Did it invent facts? Did it claim coverage that isn't mentioned in the retrieved documents? In a health insurance context, hallucinated information can directly mislead members about their benefits.
Grounding -- Does the answer incorporate all relevant information from the context to answer the user query?

This criterion checks whether the LLM actually used the retrieved information. If the chunks contain relevant details that the model ignored, the response is incomplete -- even if it didn't hallucinate.
Together, these three criteria cover the full RAG pipeline: Was the right information retrieved? (Sufficiency) Did the model stay faithful to it? (Hallucination) Did the model actually use it? (Grounding)
Experiments and Results
Overall Results
Running the full test set of 47 queries against our RAG system produces an overall score of 90.1%.
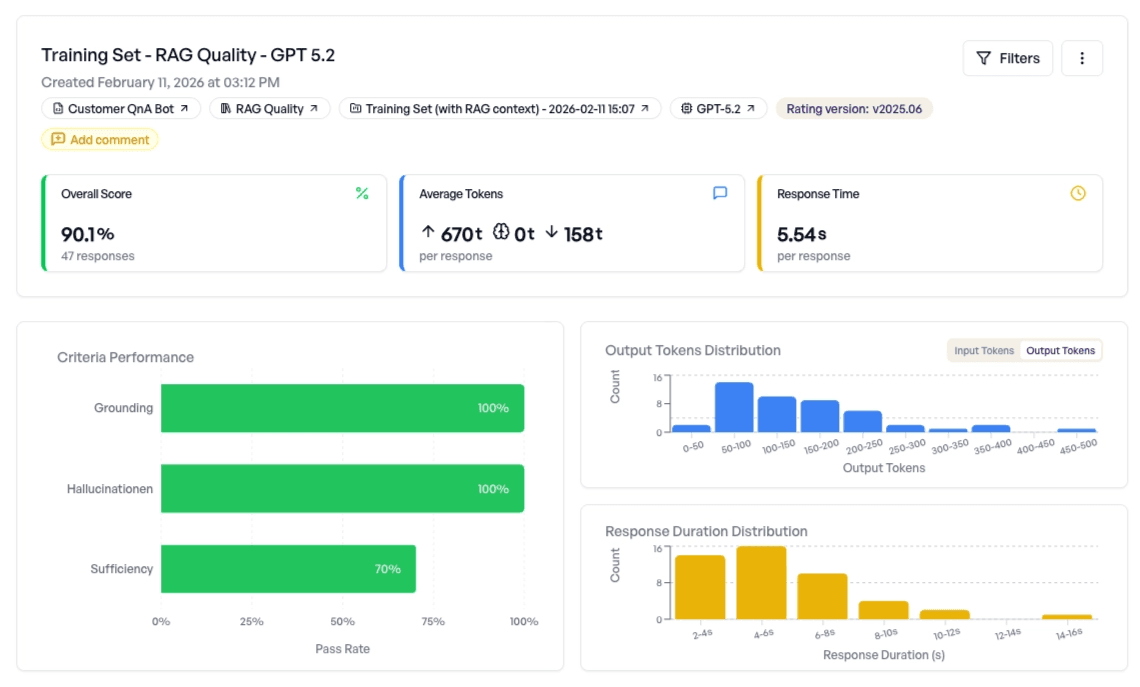
Breaking this down by criterion:
- Grounding: 100% -- The model always uses the retrieved context in its answers.
- Hallucination: 100% -- The model never invents information beyond what's in the context.
- Sufficiency: 70% -- The retrieval pipeline doesn't always find the right information.
The pattern is clear: the LLM itself performs perfectly, but the retrieval component is the weak link. Sufficiency at 70% means that for roughly 1 in 3 queries, the retrieved documents don't contain what's needed to answer the question.
But is that actually a problem? This is where the category filters become invaluable.
Where Failures Actually Matter
Filtering to only insurance-related queries -- the questions the system is actually supposed to answer -- the overall score jumps to 92.1% and Sufficiency improves from 70% to 76%. Some retrieval failures are concentrated in off-topic and out-of-scope queries. For the questions the system is designed to handle, retrieval works noticeably better.
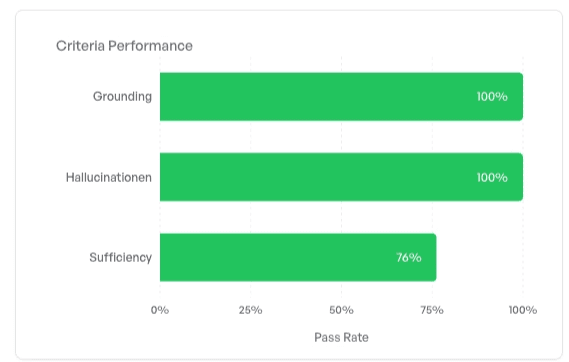
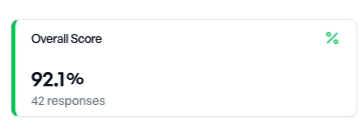
At the other end of the spectrum, off-topic queries like "What's the weather tomorrow?" show Sufficiency at just 20% -- nearly all retrieval attempts fail to find relevant context. This is exactly correct behavior. The retrieval pipeline shouldn't find relevant chunks about weather in a health insurance knowledge base. And with Grounding and Hallucination still at 100%, the model handles the absence of relevant context gracefully: it doesn't invent answers.
Without the two-axis categorization, this nuance would be invisible. We'd just see a 70% Sufficiency score and wonder what's going wrong. With proper categorization, we can immediately see that the "failures" are concentrated exactly where they should be -- and focus attention on the ones that matter.
Closing the Loop with Domain Experts
But 76% Sufficiency on insurance queries still means some legitimate questions fail. This is where the human-in-the-loop becomes essential.
Take the cosmetic surgery example from the opening. The automated evaluation correctly identified a Sufficiency failure -- the retrieved chunks covered dental services, cancer screening, and international coverage, but nothing about cosmetic surgery. The system correctly declined to answer.
But is this a problem that needs fixing? Only someone with domain knowledge can make that judgment:
- If SGKK does cover cosmetic surgery and the information should be in the knowledge base, then this is a real retrieval failure that needs attention.
- If SGKK doesn't cover it, then this is expected behavior.
In this case, a domain expert reviewed the failure and recognized a real problem: SGKK does cover certain cosmetic procedures, but the relevant policy document was never added to the knowledge base. They documented this finding, transforming a vague "Sufficiency failure" into a concrete, actionable task: ingest the cosmetic surgery policy document. When the retrieval team adds the missing document and re-runs the experiment, they can immediately check whether this specific failure is resolved -- closing the loop from discovery to fix.
This feedback loop between domain experts and engineering teams is what makes RAG evaluation practical. The automated criteria surface the right cases for review; the expert provides the judgment calls that automated systems can't make on their own.
From Testing to Production Monitoring
The same criteria that validated the test set can monitor production traffic continuously. Each day, a batch of real user queries -- with their retrieved context -- is evaluated automatically.
Over five days of monitoring, the daily scores paint a clear picture:
| Day | Overall | Grounding | Hallucination | Sufficiency |
|---|---|---|---|---|
| Day 1 | 86.7% | 100% | 100% | 60% |
| Day 2 | 96.7% | 100% | 100% | 90% |
| Day 3 | 90.0% | 100% | 100% | 70% |
| Day 4 | 90.0% | 100% | 90% | 80% |
| Day 5 | 93.3% | 100% | 100% | 80% |
Grounding and Hallucination are near-perfect, while Sufficiency fluctuates depending on the mix of queries each day. But Day 4 reveals something new: a Hallucination failure. A user asked "Where can I find my insurance number?" and the model responded confidently that the number can be found on the health insurance card and via the service app. The retrieved context mentioned the insurance number and the app, but never explicitly confirmed that the number is printed on the card. The model inferred this -- a reasonable assumption, but one not directly supported by the sources.
This is exactly the kind of nuanced failure that matters in production. The answer is plausible, but in a regulated domain, the distinction between "probably true" and "verified from sources" is critical.
Daily production monitoring provides three key benefits:
- Early warning. If the retrieval index gets corrupted, a model update introduces regressions, or the knowledge base becomes stale, daily evaluation catches it before users notice.
- Trend visibility. Instead of anecdotal reports, you have objective metrics over time -- broken down by criterion, so you know what changed, not just that something changed.
- Actionable diagnostics. When a score dips, the criterion breakdown tells you whether it's a retrieval problem (Sufficiency), a generation problem (Hallucination), or a completeness problem (Grounding) -- pointing directly at which component to investigate.
What Makes RAG Evaluation Work
- Structure your test set with intention. Two-axis categorization transforms a flat list of test queries into a diagnostic tool. When something fails, you can immediately narrow down whether it's a retrieval problem, a generation problem, or expected behavior.
- Design criteria that isolate failure modes. Sufficiency, Hallucination, and Grounding each target a different component of the RAG pipeline. When a score drops, you know exactly where to look.
- Accept that not all failures are equal. A 0% Sufficiency score on off-topic queries is a feature, not a bug. Automated evaluation surfaces the cases; domain experts provide the judgment. Building this human-in-the-loop process into your evaluation workflow is essential.
- Monitor production continuously. A test set validates your system under controlled conditions. Production monitoring validates it under real conditions, every day, with the messy diversity of actual user queries.
Building a RAG system is the first step. Knowing that it works -- and continuing to verify that it works -- is what gets it to production and keeps it there.
Looking for technical implementation details? For a hands-on technical guide using the elluminate SDK -- including code examples for setting up evaluation pipelines programmatically -- check out our RAG Evaluation Documentation.
Whether you're building a customer-facing chatbot or an internal knowledge assistant, elluminate gives you the tools to evaluate systematically -- from test design to production monitoring. We'd be happy to help you get started.
Get in Touch