Three months after launch, someone on the team asks in standup: “Wait, has anyone actually been checking what the model is telling our users?” Silence.
That silence has a pattern. We see it a lot in our own work at ellamind as well as in conversations with teams building AI-powered products:
- A team builds a prompt or agentic workflow that produces good results in testing.
- The system goes into production. Outputs look reasonable.
- Quality checks exist, but they're shallow: someone skims a few responses, maybe runs a test set occasionally until something goes wrong and the first question is: “Didn't anyone check this?”
The uncomfortable answer is usually that checking was everyone's job and therefore nobody's job. Quality ownership drifted from the team that built the system to “monitoring” or “QA will catch it.”
This drift isn't unique to AI. But AI makes it worse, for a specific reason.
The Plausibility Trap
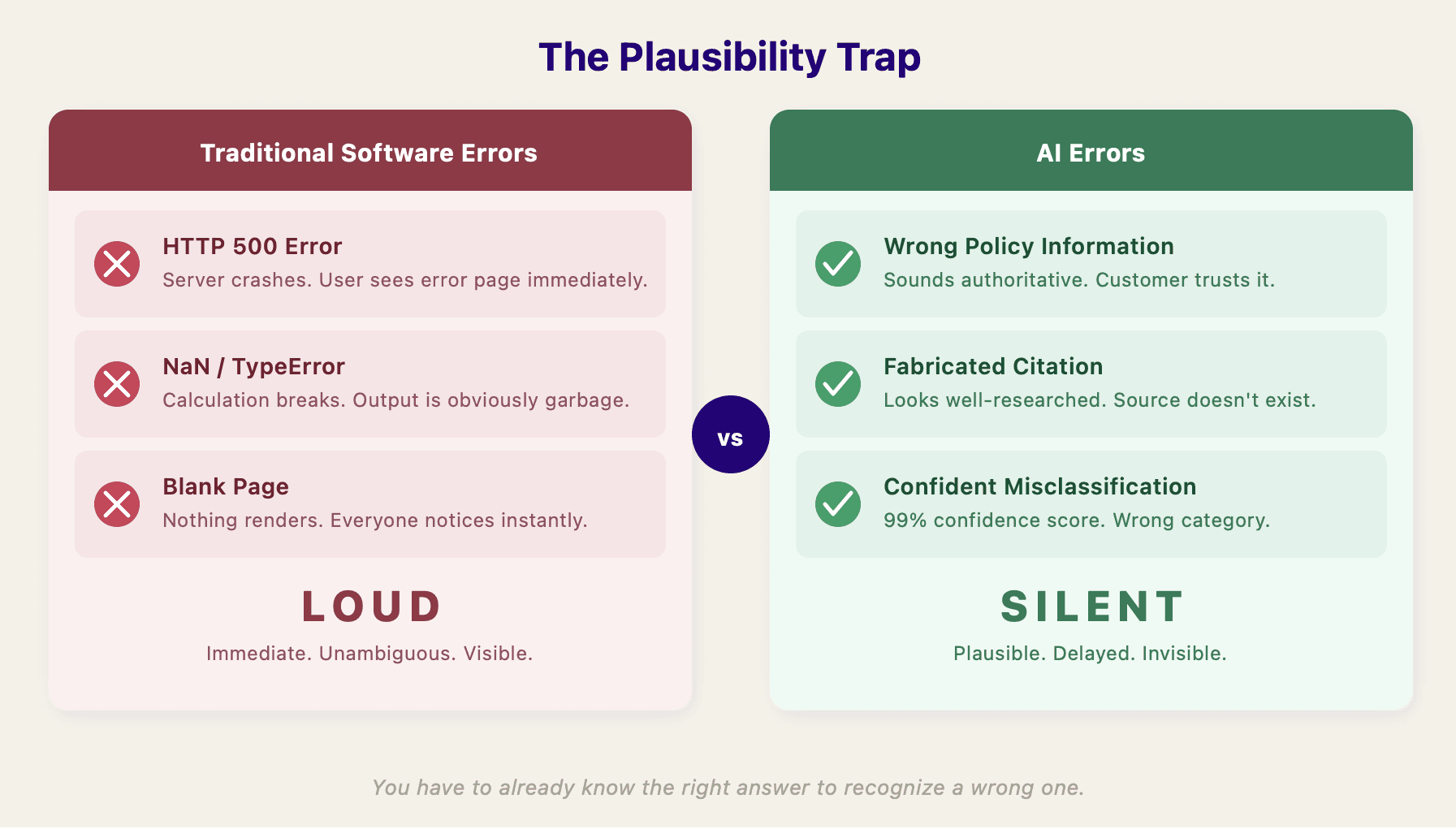
Traditional software mostly fails loudly. An API returns a 500, a calculation produces NaN, a page doesn't load. These failures are visible, immediate, and unambiguous.
AI systems fail quietly. Air Canada's chatbot confidently gave a customer incorrect bereavement fare information. The airline was ordered to pay damages. New York City's MyCity chatbot told entrepreneurs they could legally take workers' tips and serve rodent-nibbled food. In both cases, the outputs sounded authoritative. Nobody noticed until real damage was done.
Research backs this up: language models use more confident language — words like “definitely” and “certainly” — when they are hallucinating. The worse the error, the more convincing the delivery.

This is similar to a well-known problem in quality assurance. Your brain is remarkably good at filling in what it expects to see. There's a classic experiment where the words CAT and THE are written by hand, with the A and the H drawn identically wrong. Everyone reads both words perfectly. Our visual system just supplies the corrections. The same thing happens when you read a plausible AI response: your brain fills in the gaps, resolves ambiguities, and rounds up to “looks right.” QA has dealt with this for decades by defining measurable criteria upfront that don't rely on human interpretation. The same principle applies here.
AI outputs are plausible by default. You have to already know the right answer to recognize a wrong one. “Someone will notice” is not a quality strategy. By the time someone notices, the damage is done: a customer received wrong information, a decision was made on a flawed summary, a process moved forward based on a misclassification.
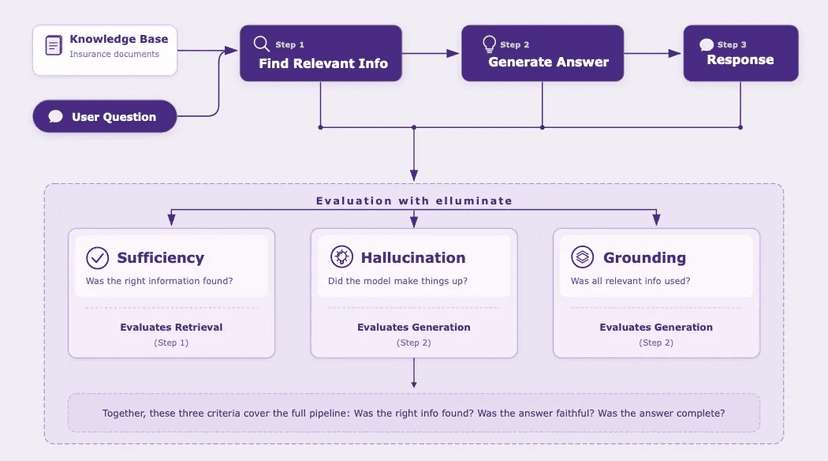
Systematic evaluation with defined criteria, representative test sets, and binary pass/fail judgments is how you catch what casual inspection misses. The binary part is a deliberate choice: it forces you to decide what “good enough” actually means, rather than hiding behind a 3.7 out of 5.
What Ownership Actually Means
Here's the principle we keep coming back to, whether we're talking about our own features or working with teams who use elluminate:
The team that deploys the AI system owns the correctness of its outputs. Evaluation verifies that correctness — it doesn't create it.
That sounds obvious. But in practice, it changes how you work. Owning quality doesn't mean personally reviewing every AI response. It means:
Define what “correct” means before you ship. Not after the first customer complaint. Not vaguely (“it should be helpful”). Concretely: what must this output contain? What must it never say? What edge cases matter? We've seen teams struggle with this step. If you can't write it down as evaluation criteria, you probably don't yet understand your own system well enough to put it in front of users.
Prove correctness with evidence, not intuition. “We tested it and it seemed fine” is not evidence. Evidence looks like: “We ran 200 representative queries across 5 categories, evaluated each response against 4 binary criteria, and achieved a 94% pass rate with the remaining failures concentrated in [specific area].” One of those is something you can act on. The other is hope.
Treat evaluation as defense-in-depth, not a safety net. When a bad output reaches a user, the response isn't “evaluation should have caught it.” It's “we need to understand why our system produced this and what to change.” And then update the evaluations so they catch it next time.
What This Looks Like in Practice
Say you're building a RAG-based support bot for a health insurance company. A customer asks about cosmetic surgery coverage.
Without ownership structure: An engineer checks that the bot returns something. The response looks reasonable. It ships. Three weeks later, customer service reports that the bot has been telling people certain procedures aren't covered when they actually are. The policy document was in the knowledge base, but retrieval missed it, and nobody had defined “correct” well enough to catch the gap.
With ownership structure: Before shipping, the team sits down with a claims specialist. Together they write criteria:
- “Response must reference the specific policy section.”
- “If coverage depends on medical necessity, the response must say so.”
- “If the relevant document isn't retrieved, the response must not guess.”
They build a test set of 50 real questions, including tricky edge cases the claims team has seen before. They run evaluations after every prompt change. When retrieval fails on the cosmetic surgery question, they catch it in development, not from a frustrated customer.
We saw exactly this pattern play out in our RAG case study: automated evaluation flagged a retrieval failure, but only a domain expert could judge whether it was a real problem or expected behavior. An engineer would have seen “retrieval miss” and moved on. The domain expert saw a gap that affected real members.
The difference isn't more process. It's knowing what “right” looks like before you ship, and checking against it.
Making It Work
The example above shows what ownership looks like for one team in one domain. Here's the general playbook — what to do regardless of what you're building.
Write your criteria before you ship. For every AI feature, define binary pass/fail criteria: “The response must reference the correct policy section.” “The summary must include all action items.” “The classification must match the ground truth label.” Vague criteria produce vague quality.
Write them with domain experts, not just engineers. This is where most teams go wrong: engineers write the criteria alone. They can test structure, consistency and technical constraints, but they don't know which simplification of a coverage rule crosses the line from helpful to harmful. A health insurance chatbot that “returns a response within the expected format” can still give dangerously wrong advice about coverage. Good criteria need both perspectives at the same table: the domain expert who knows what a correct answer looks like, and the engineer who knows what's measurable.
Build a representative test set. Not your ten favorite examples. A set that covers the range of inputs your system actually handles: the hard cases, the edge cases, and the cases where you've seen failures before. This is your ground truth.
Scale rigor to risk. Not every AI output needs the same level of scrutiny. Tie evaluation depth to the cost of getting it wrong:
| Risk | Examples | What to do |
|---|---|---|
| Low | Internal summaries, drafts, suggestions | Automated checks, spot sampling, lightweight criteria |
| Medium | Customer-facing responses, recommendations, classifications | Most chatbots and RAG systems live here, and this is where most quality failures happen. Structured evaluation against defined criteria. Regular test set runs. Human review of a representative sample. |
| High | Medical, legal, financial, compliance outputs | Comprehensive test sets covering edge cases. Multiple criteria per output. Documented evidence. Audit trail. The EU AI Act Article 17 is making this level of rigor a legal requirement for high-risk AI systems. |
Even at the lowest tier, someone has decided what “correct” means and is checking against it. The alternative is finding out about quality problems from your users.
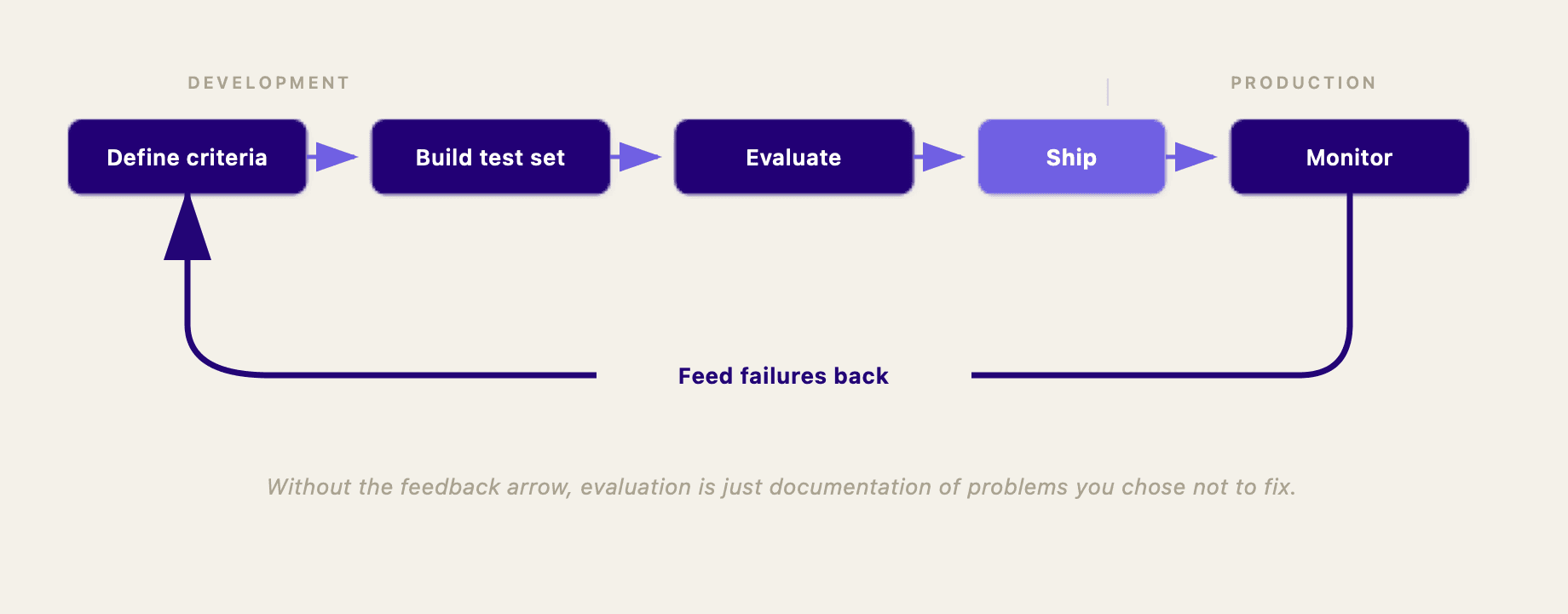
Evaluate during development, and keep evaluating in production. Every prompt change, every retrieval tweak, every model swap should be tested against your criteria before it reaches users. But don't stop once you ship. AI systems drift as models update, data changes, and user behavior shifts. Development evaluation tells you “good enough to ship.” Production evaluation tells you “still good enough to keep running.”
Close the loop. When evaluation reveals failures, trace them back to root causes. Fix whatever produced the bad output — be it the prompt, the retrieval, the guardrails. Then add that failure case to your test set so you catch it next time. Evaluation without a feedback loop is just documentation of problems you chose not to fix.
At ellamind, we build the evaluation platform elluminate that makes this kind of systematic AI quality assurance practical — from defining criteria with your domain experts to evaluating during development and production. If this is a problem you're solving, we'd love to talk.