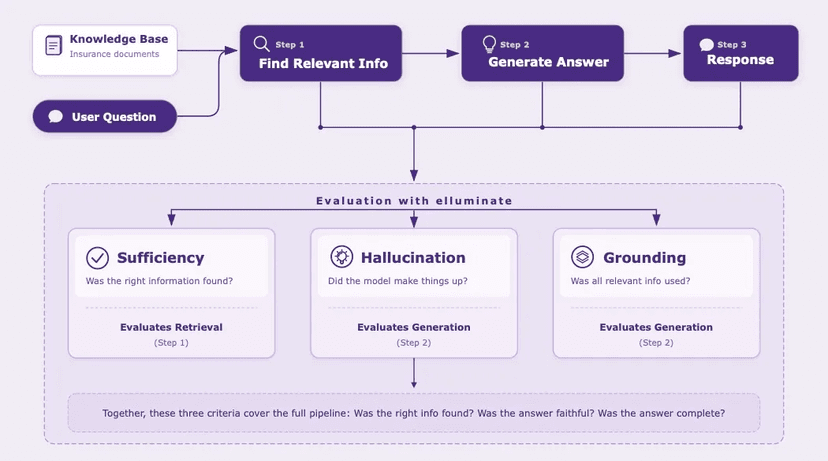
In December 2025, OpenAI released FrontierScience, the hardest public science benchmark to date. Since then, a new generation of frontier models has shipped: GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro. With each promising a major leap in performance, we wanted to see where things stand now. In this post, we re-run the benchmark on the latest models using elluminate and break down the results.
OpenAI's FrontierScience benchmark
As the reasoning capabilities of AI models keep on scaling, existing science benchmarks have struggled to keep up. GPQA[2], once considered super difficult, saw model scores jump from 39% to 92% in two years. FrontierScience was built to be harder, more original, and more meaningful. It contains 160 problems across physics, chemistry, and biology, written by 42 international olympiad medalists and 45 PhD scientists. Every problem was peer-reviewed by independent domain experts, and problems that OpenAI's internal models could already solve were discarded during construction, which makes the strong GPT-5.4 result later all the more interesting. Here's one of the simpler examples, from the chemistry Olympiad set:
Problem: Chlorine perchlorate (Cl₂O₄) is an interesting oxide of chlorine. The chlorine atoms have different oxidation states. What is the product of their oxidation states?
Answer: 7
This is on the easier end. Most problems are significantly harder. They require multi-step synthesis chains, lengthy derivations, or experimental design tasks that require combining knowledge across subfields.
The benchmark has two subsets. Olympiad contains 100 problems with a single correct answer: a number, equation, formula, or short phrase. Research contains 60 open-ended subtasks representative of what a PhD scientist might encounter during their research, each designed to take three to five hours and graded on a 10-point rubric.
For this evaluation, we focused on the Olympiad subset: 100 difficult problems with verifiable answers. Here's how we set it up in elluminate.
Importing the dataset
OpenAI made the FrontierScience dataset openly-accessible on HuggingFace. Importing the Olympiad subset into elluminate is pretty straightforward using the Python-SDK: we filter out the Research track (its answers start with "Points:"), strip the baked-in instructions, and create a collection:
import datasets as hfds
from elluminate import Client
COLUMNS = ["problem", "reference_answer", "subject"]
# Full instruction text truncated for readability
INSTRUCTION_OLYMPIAD = 'Think step by step and solve the problem below. At the end of ...'
client = Client()
ds_en = hfds.load_dataset("openai/frontierscience") ["test"]
ds_en = ds_en.filter(lambda x: "Points:" not in x["answer"])
ds_en = ds_en.map(lambda x: {"problem": x["problem"].replace(INSTRUCTION_OLYMPIAD, "").strip()})
ds_en = ds_en.rename_column("answer", "reference_answer")
client.create_collection(
name="FrontierScience Olympiad",
variables=ds_en.select_columns(COLUMNS).to_list(),
)Here is what it looks like in the web-UI:
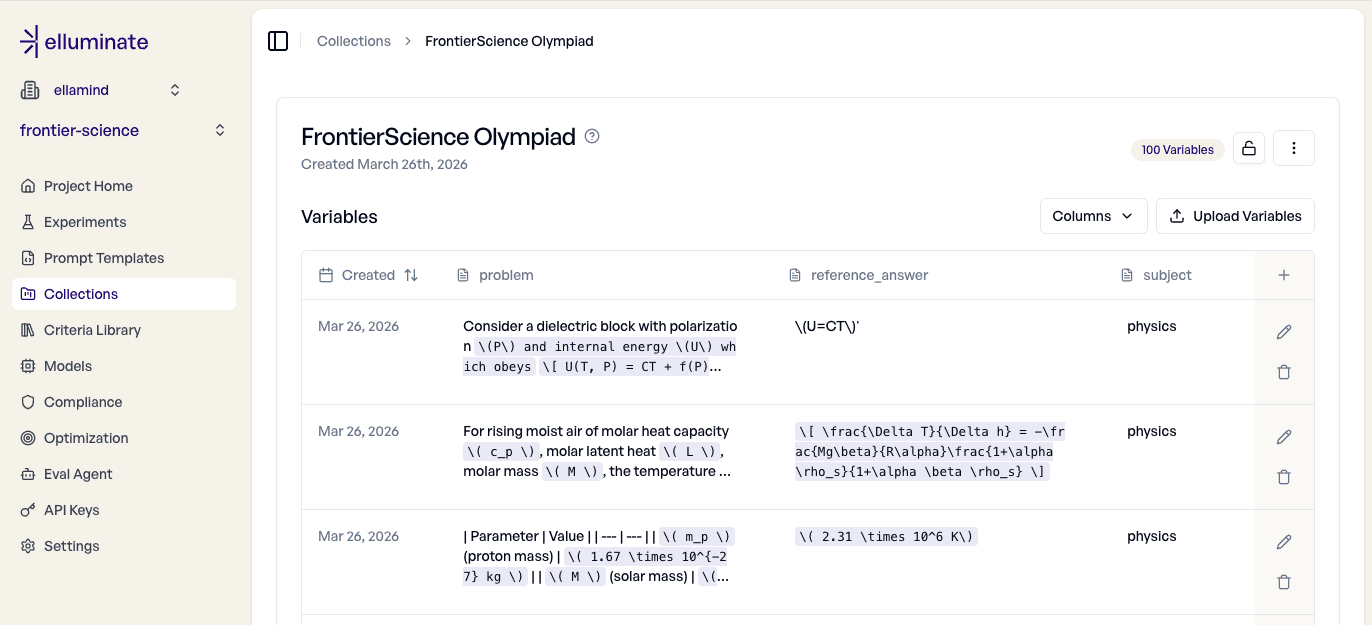
The subject column lets us filter by discipline later, so we can compare model performance between biology, chemistry and physics.
Setting up prompt template and criteria
Beyond the collection, we need two more things: a prompt template that tells the model what to do, and a set of criteria that tell the rating model how to score responses.
Following OpenAI's FrontierScience implementation, our prompt template wraps each problem with instructions to solve step by step and write a final answer. Each (problem) placeholder gets replaced with a problem from the collection at evaluation time.
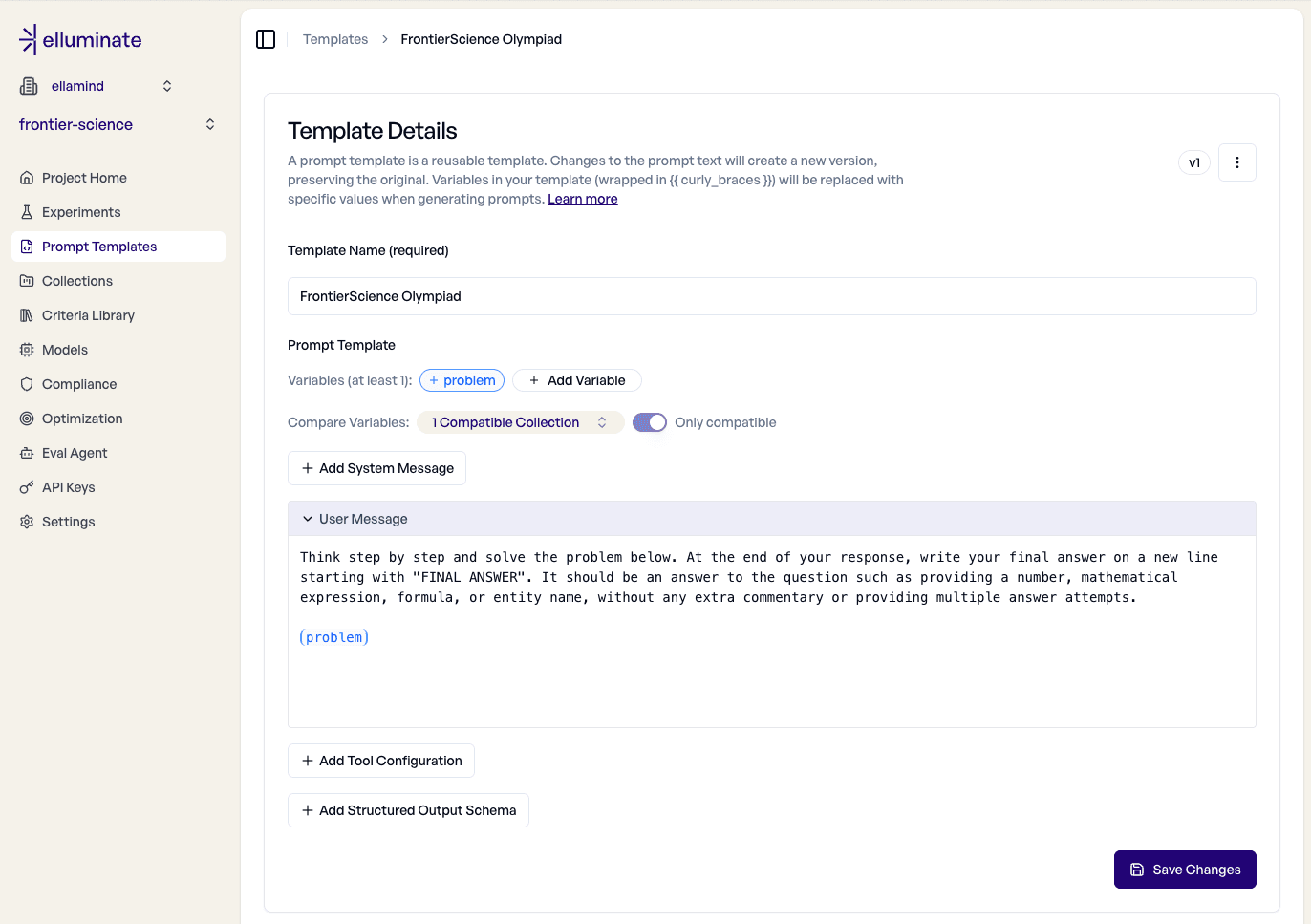
For evaluating the Olympiad subset of FrontierScience, we only need a single criterion: Does the model's final answer match the reference? We also want to accept equivalent forms: matching algebraic expressions, numbers within one decimal place of rounding, equivalent compound names, and unit conversions.
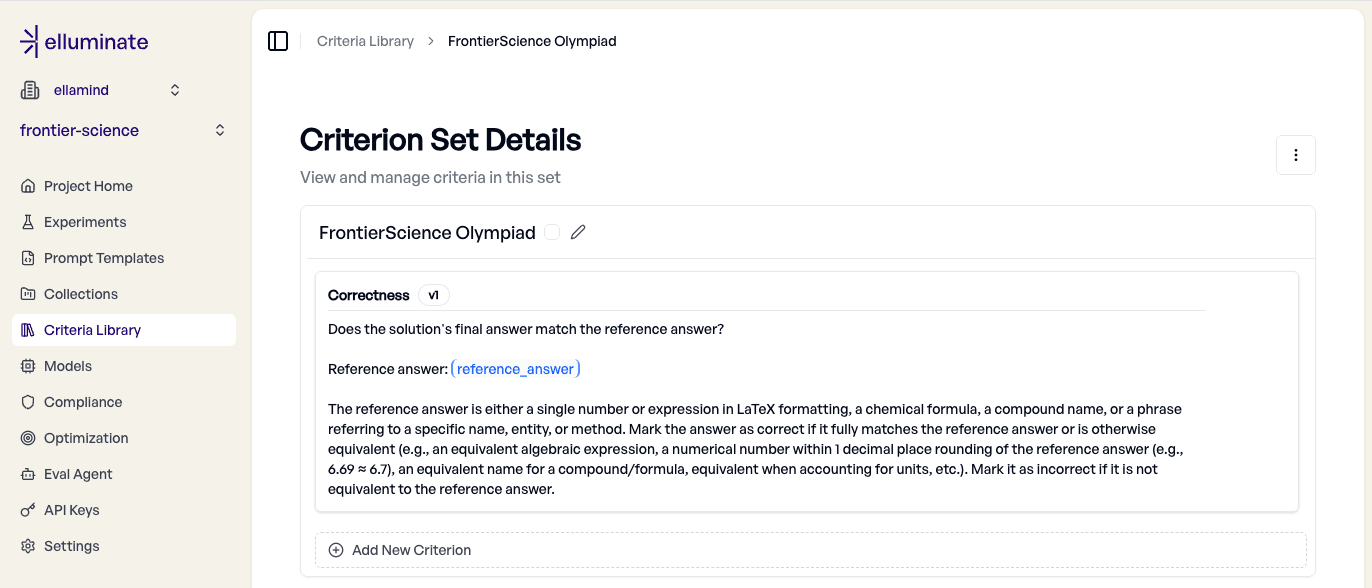
We adapted this criterion directly from the judge prompt OpenAI published in their paper[1].
Running the experiments
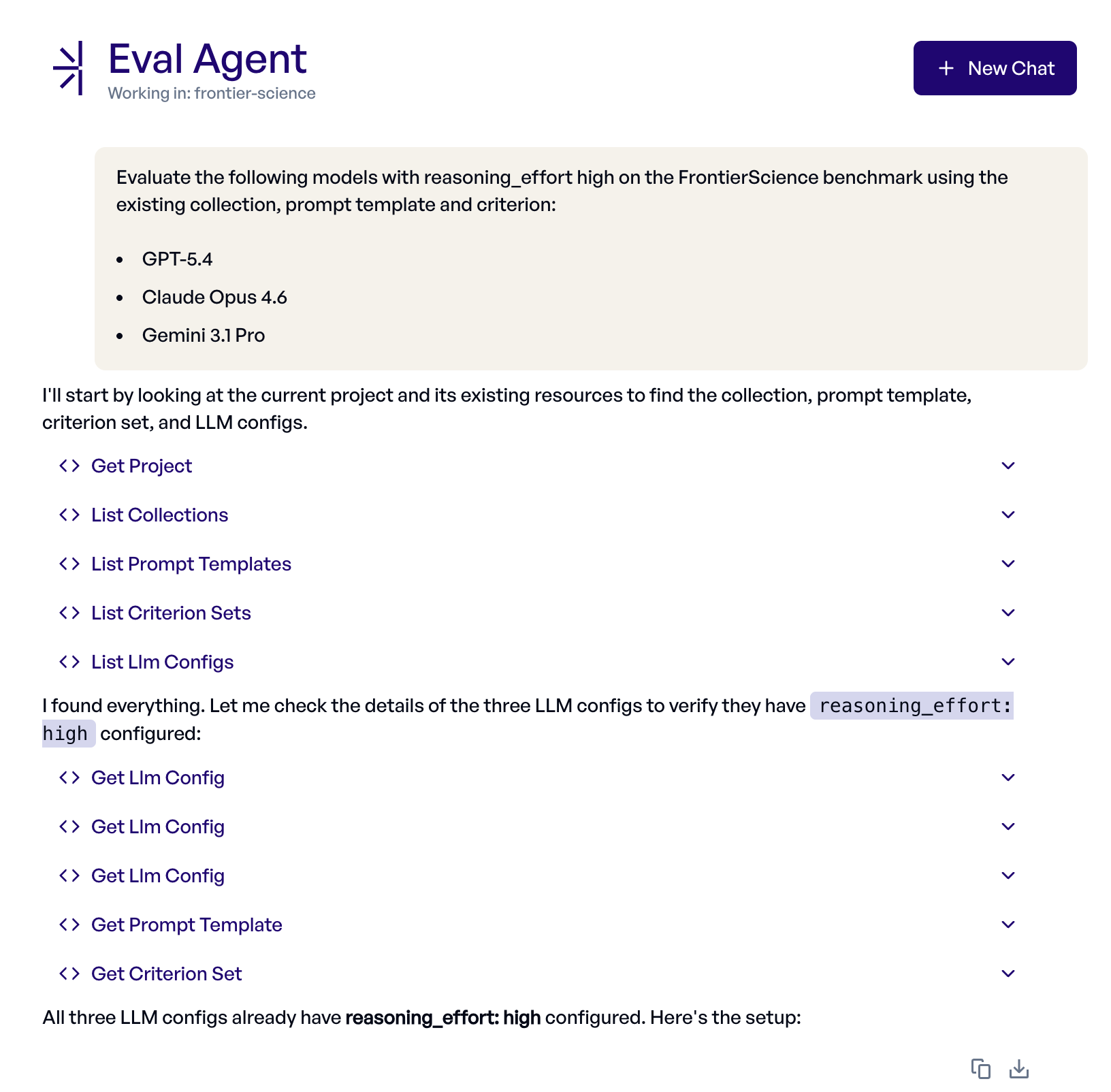
We are now well prepared to kick off some experiments. Let's hand this off to elluminate's Eval Agent, an AI assistant built into the platform that can create, run and interpret experiments from a natural-language prompt.
We gave it the following instruction:
Evaluate the following models with reasoning_effort high on the FrontierScience benchmark using the existing collection, prompt template and criterion:
- GPT-5.4
- Claude Opus 4.6
- Gemini 3.1 Pro
The Eval Agent creates and starts one experiment for each of the requested models, configuring and running everything on its own. Here is its trace:
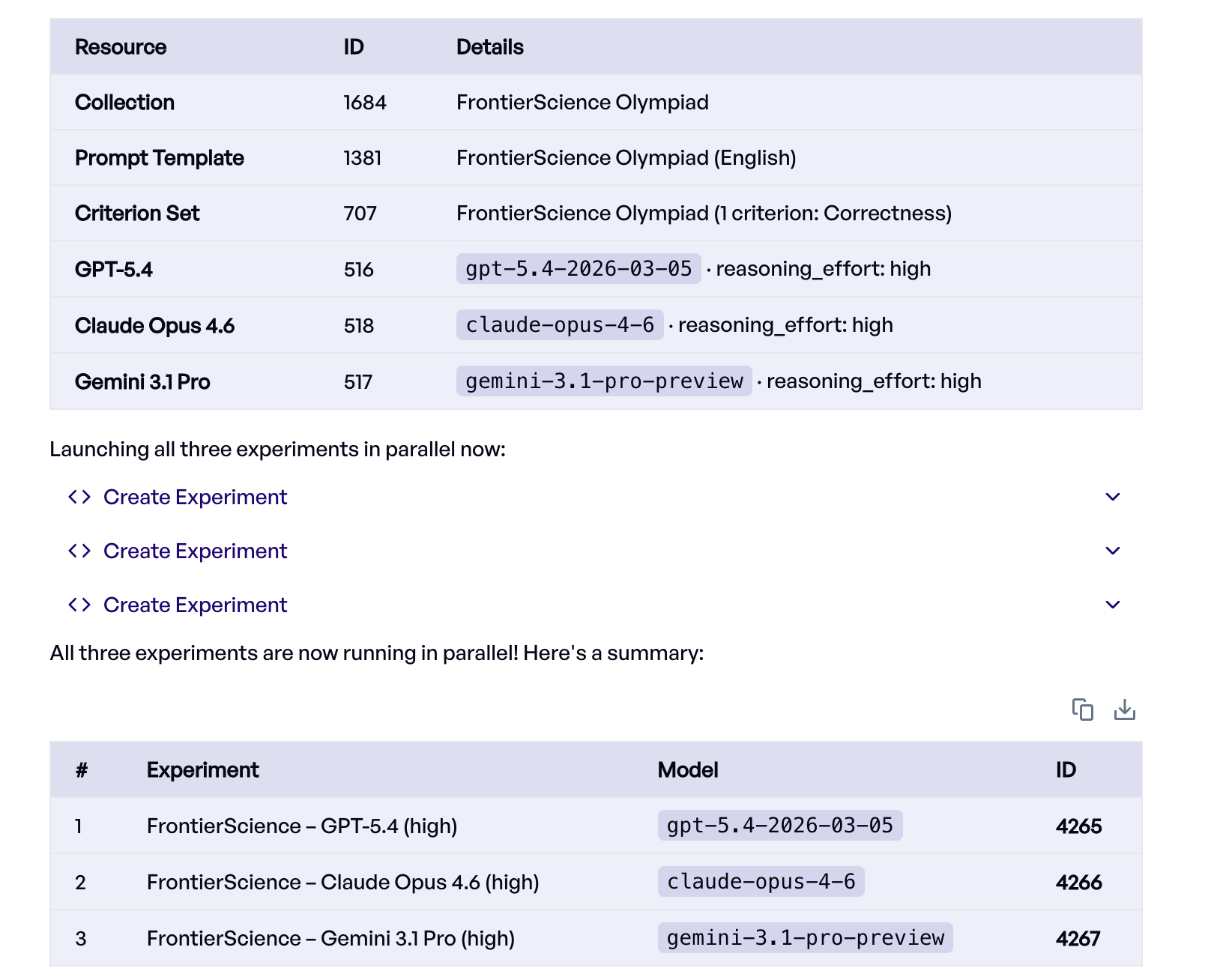

Let's monitor the progress in the experiments dashboard:
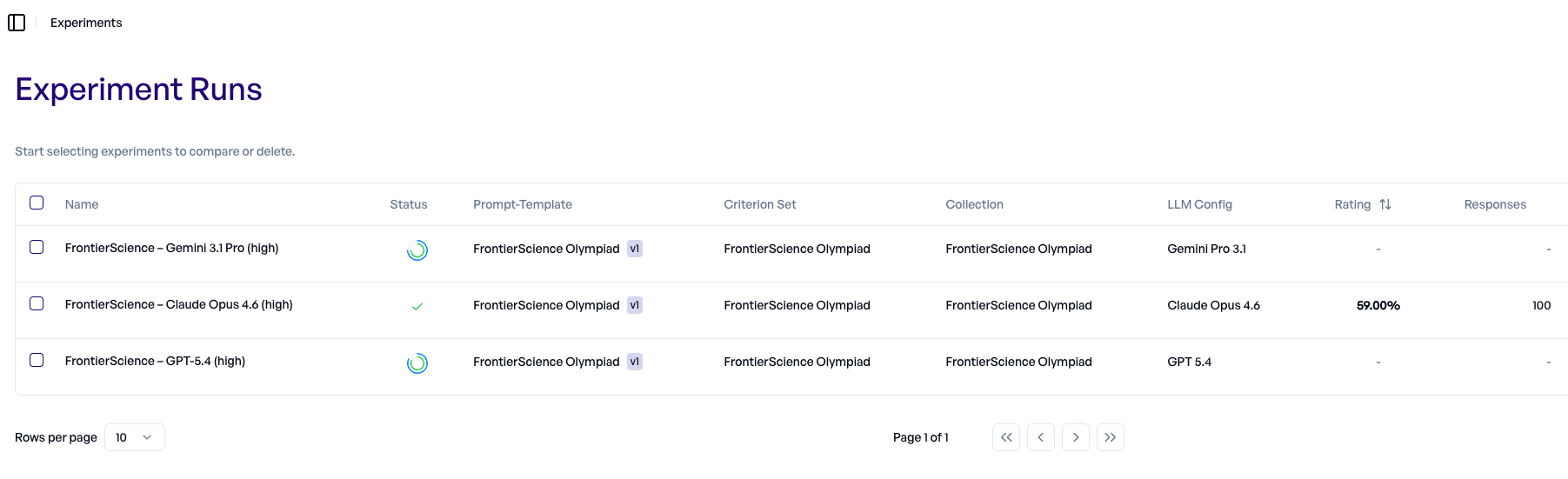
Claude already finished, while Gemini 3.1 and GPT 5.4 are still running.
Interpreting the results
Once all experiments finish, we ask the Eval Agent to analyze them:
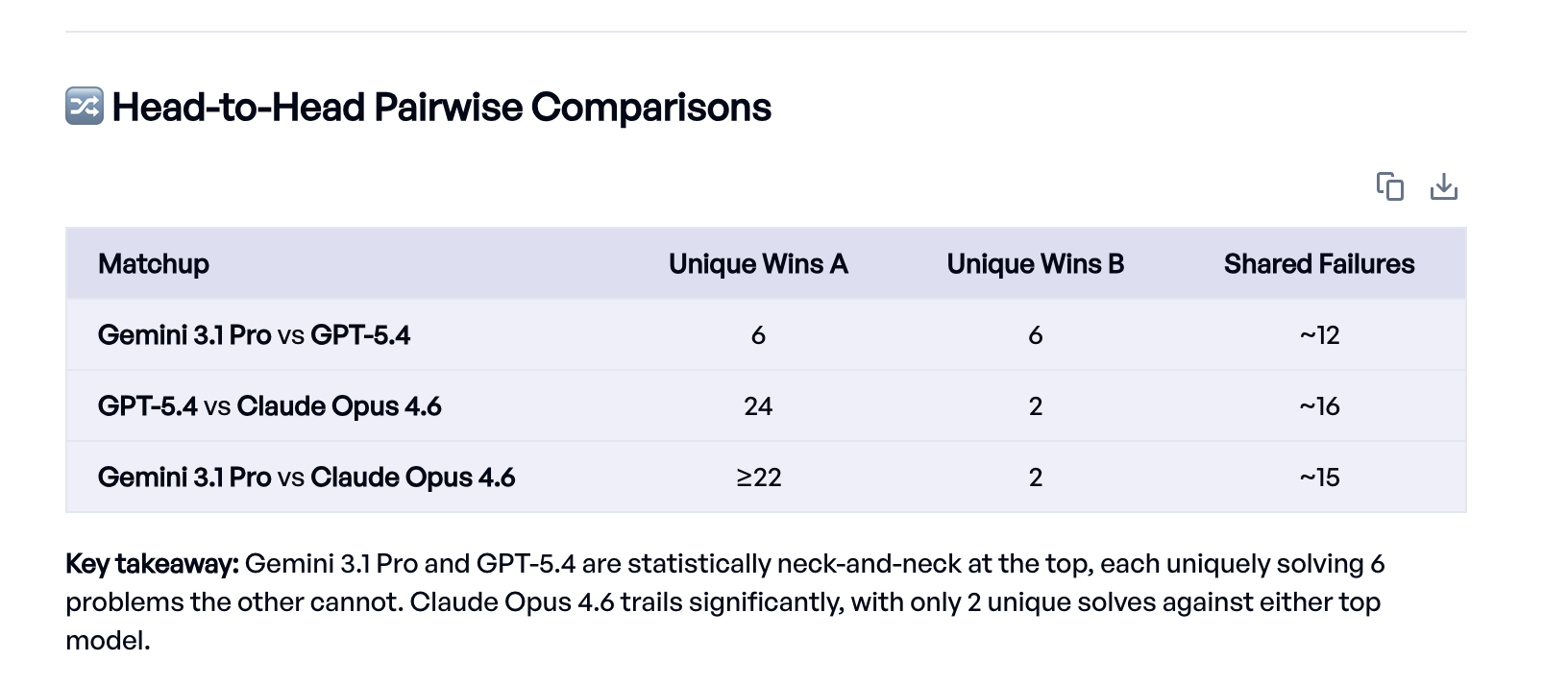


The Eval Agent went beyond just reading the scores. It pulled the results from each experiment, ran pairwise comparisons to find problems that one model solved but another didn't, looked at specific failure examples, and identified common error patterns like sign errors and dropped terms.
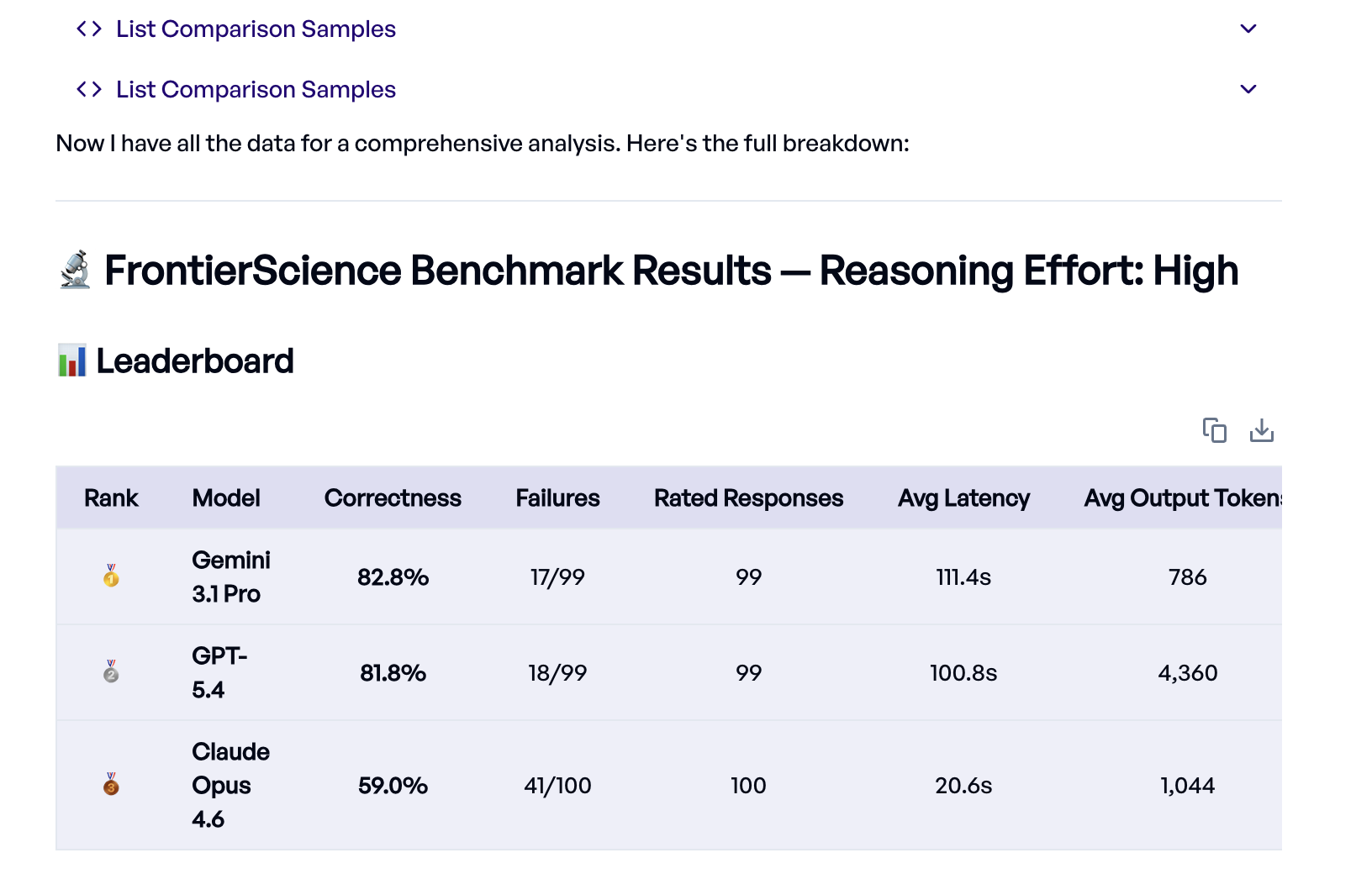
The headline result: Gemini 3.1 Pro and GPT-5.4 are nearly tied at the top (82.8% and 81.8%), while Claude Opus 4.6 trails at 59%.1
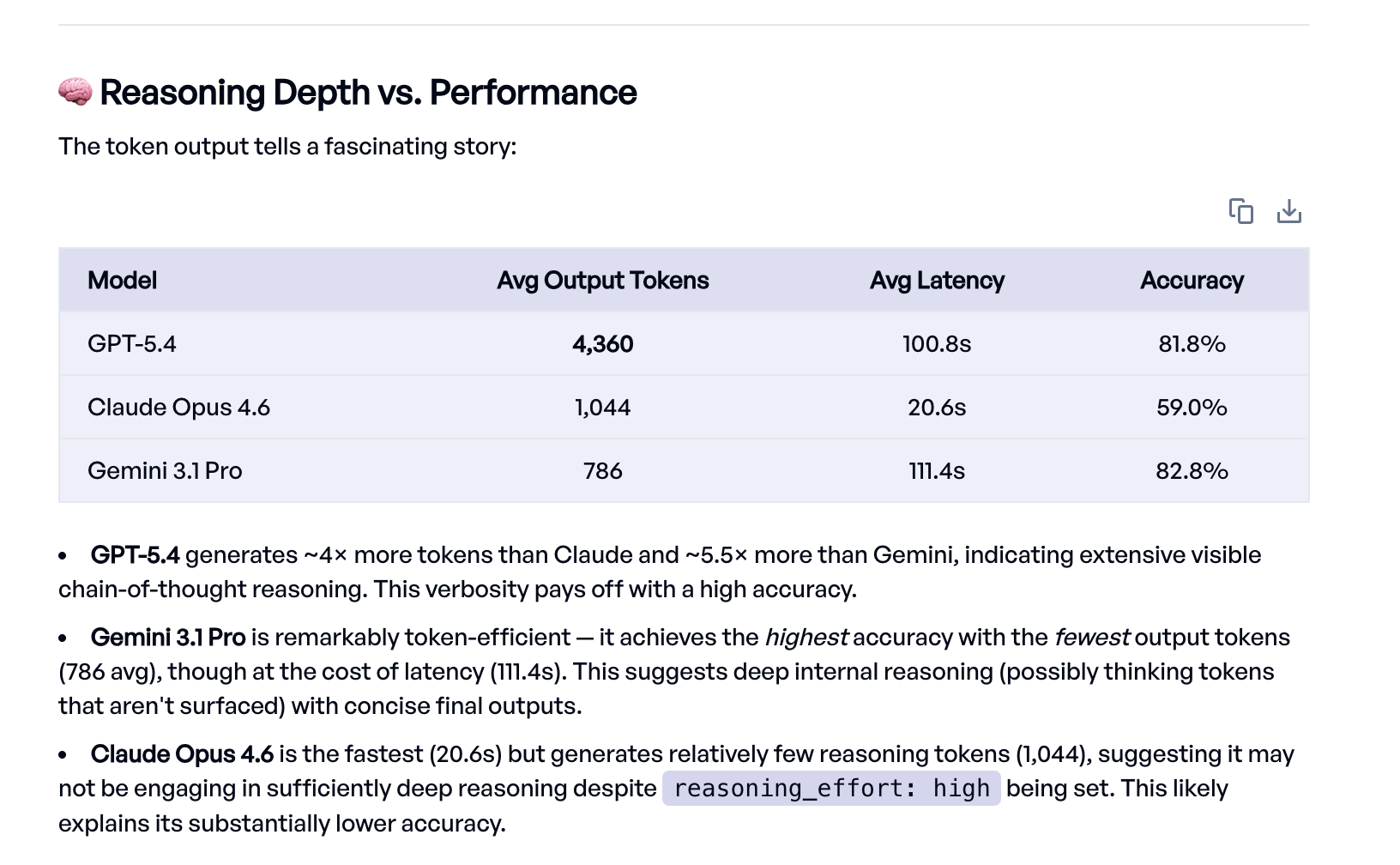
One interesting detail the Eval Agent surfaced is the relationship between output length and accuracy. GPT-5.4 generates roughly 4,000 tokens per response with extensive visible chain-of-thought reasoning, while Gemini achieves slightly better accuracy with under 800 tokens. Claude produces the shortest responses and is by far the fastest, but the lower token count may indicate it isn't reasoning deeply enough on these problems. A natural next step would be optimizing the prompt to push Claude towards deeper reasoning.
Subject-level breakdown
We also asked the Eval Agent for a per-subject breakdown:
| Model | Physics (50) | Chemistry (40) | Biology (10) |
|---|---|---|---|
| Gemini 3.1 Pro | 80.0% | 95.0% | 50.0% |
| GPT-5.4 | 78.0% | 95.0% | 50.0% |
| Claude Opus 4.6 | 56.0% | 70.0% | 30.0% |
| Avg. across models | 71.3% | 86.6% | 43.3% |
Chemistry is nearly solved. Both GPT-5.4 and Gemini 3.1 Pro score 95%, failing just 2 problems each.
Physics is harder but still in reach at ~80%.
Biology is the clear weak spot. None of the models manages to solve more than half. These are experimental biology problems (molecular cloning, scRNA-seq, signaling pathways) requiring specialized wet-lab domain knowledge. With only 10 problems in the subset, the numbers should be taken with a grain of salt, but the difficulty is consistent across all three models.
Claude's gap is consistent across all three subjects, not concentrated in one area. Combined with the shorter output lengths noted above, this suggests a systematic difference in reasoning depth rather than a domain-specific weakness.
What's next
Three months ago, the best model scored 77% on these problems. Now two models are above 82%, and chemistry is nearly solved at 95%. Physics is in reach. The biology problems remain unsolved at the frontier. But at the current pace of progress, probably not for long.
With elluminate, we went from a public HuggingFace dataset to a full model comparison in no time. From here we can take this in many directions: evaluate more models, optimize the prompt template to improve a specific model's performance, or run more trials to reduce variance. The same workflow applies to any evaluation, not just science benchmarks.
If you would like to try elluminate yourself, reach out and we'll help you get started. We support all kinds of use-cases, including agentic evaluation.
References
- Wang, M., Lin, R., Hu, K., Jiao, J., Chowdhury, N., Chang, E., & Patwardhan, T. (2026). FrontierScience: Evaluating AI's Ability to Perform Expert-Level Scientific Tasks. arXiv:2601.21165
- Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022
Get in touch and we'll help you set up rigorous science benchmarks for your own models.
Get in Touch