Whether you're building LLM evaluation systems or designing rubrics for agent evaluation, teams often reach for what feels like the most "scientific" option: a 1-5 rating scale. More granularity means more information, right?
After working with dozens of teams on their AI evaluation workflows, we've learned something counterintuitive: binary yes/no evaluations consistently outperform Likert scales for pass/fail evaluation tasks. This claim is backed by research and hard-won experience from teams shipping production AI systems. Binary evaluation means asking a yes/no question: did this output meet the criteria? It's a simple reframe that changes everything.
The Appeal of Likert Scales
Let's acknowledge why 1-5 scales are popular. A "4" feels more informative than a binary "pass." We've all filled out surveys with these scales, and they're familiar. When you're unsure about a rating, that comfortable middle option is right there.
Likert scales do have their place. For sentiment analysis, user satisfaction surveys, or preference research where you genuinely want to capture degrees of opinion, numeric scales make sense. The problem arises when we apply them to evaluation tasks that are fundamentally about whether something meets a bar. Did the AI answer correctly? Did it follow the guidelines? These are yes/no questions dressed up in numeric clothing.
The Hidden Problems with Numeric Scales in AI Evaluation
Ask five people to rate the same AI response on a 1-5 scale. You'll get five different answers. They don't disagree about quality; they disagree about what "3" means. As Hamel Husain notes, "the distinction between a 3 and a 4 lacks objective definition and varies significantly among different annotators."
This compounds when evaluators are uncertain. They gravitate toward the center, a natural human tendency. Picking an extreme feels like a commitment, while "3" feels safe. Your rating distribution piles up in the middle, drowning out the signal.
The statistical consequences are real. Detecting meaningful differences with Likert scales requires significantly larger sample sizes. If your average rating moves from 3.2 to 3.5, is that progress or noise? With binary evaluations, the math is cleaner: going from 60% to 70% pass rate is unambiguous.
When you use LLMs as evaluators, these problems compound. LLMs are text generators, not calibrated for precise numeric scoring. Research shows that LLM evaluators achieve higher recall and precision on binary classifications than on numeric scales.
The Case for Binary Evaluations
Binary evaluations reframe the question. Instead of "how good is this on a scale?", you ask "does this meet the bar?" It's a fundamentally different question, and a more useful one.
When you design a binary criterion, you have to define what "pass" actually means. This forces you to articulate your quality bar explicitly. Your team aligns on what quality looks like, and your evaluators, human or AI, can apply the bar consistently.
The results are immediately actionable: a pass rate of 73% connects directly to decisions ("we're at 73%, our target is 85%"), while an average score of 3.4 leaves you wondering what to do next. Stakeholder communication gets easier too. Explaining "89% pass rate" is straightforward; explaining "average score improved from 3.4 to 3.7" invites questions you don't want to answer. In short, binary criteria produce more consistent ratings across evaluators, require smaller sample sizes to detect improvements, and translate directly into actionable pass rates.
The Power of Explanations
Here's something often overlooked: the real information lives in the reasoning behind the score, not the score itself.
When an LLM evaluator gives you a "3," you're left guessing. Was it almost a 4? Barely above a 2? But when a binary evaluator says "No" and explains why, you get something far more valuable: a specific, actionable diagnosis.
This is why elluminate always provides reasoning alongside every yes/no rating. The binary decision forces clarity about whether something passed the bar, and the explanation tells you exactly why. When you're debugging a prompt that's failing 30% of the time, you need to know what specifically went wrong, not that failures averaged 2.3 on some abstract scale.
Research from Zheng et al. confirms this: prompting LLMs to explain their ratings significantly improves alignment with human judgments. Explanations fit naturally with binary formats: "yes, because..." produces clearer reasoning than justifying why something is a 3 rather than a 4.
Calibrating Your Criteria
What happens when you disagree with the model's ratings? With binary criteria, the fix is straightforward: add clarifications to your criterion. Statements like "if the response includes a disclaimer, that's acceptable" or "if the source URL is missing, rate no" resolve ambiguity without changing the fundamental question. Rerun your experiments, and you'll quickly see whether the clarification aligned the ratings with your expectations.
With Likert scales, calibration is harder. If raters disagree about whether something is a 3 or a 4, you can't just add a footnote. You end up redefining the entire scale, retraining raters, and often starting from scratch.
"But What About Nuance?"
The most common objection is that binary evaluations lose information. "Surely a response that's almost good is different from one that's completely wrong?"
Yes, and binary evaluations handle this through decomposition. Instead of one vague "quality" rating, break it into specific checkpoints:
This gives you more nuance than a single Likert rating ever could. You're tracking specific behaviors, not an abstract score. When pass rates drop, you know exactly which aspect is failing. You get granularity where it matters, without the consistency problems of subjective scales. This decomposition approach also makes it easier to build focused test sets targeting specific failure modes.
What This Looks Like in Practice
For a customer support bot, instead of "rate the helpfulness of this response (1-5)", you might ask: Did the response address the customer's question? Did it provide accurate policy information? Did it avoid making promises we can't keep? Each question has a clear yes/no answer, and together they paint a complete picture.
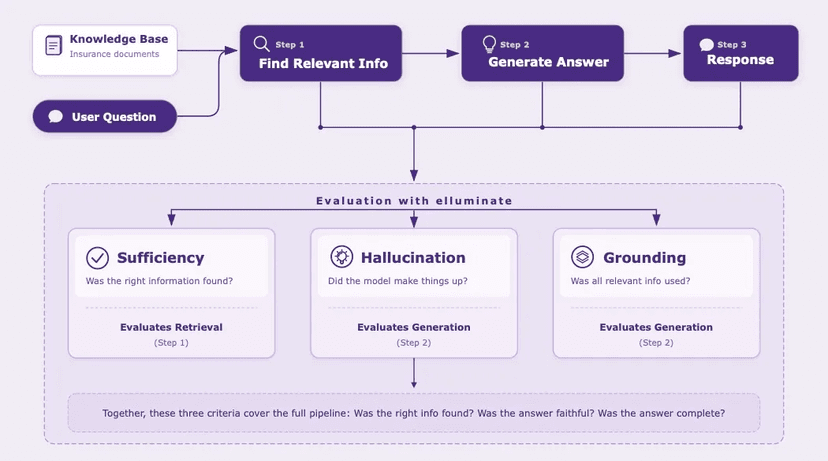
For a RAG system, you'd check: Is the answer supported by the retrieved documents? Does it include all key facts? Does it avoid introducing unsourced information?
Content moderation is naturally binary: content either violates policy or it doesn't. Decomposition helps you track violation types separately: hate speech, harassment, misinformation.
The discipline of binary evaluation also forces you to handle edge cases explicitly. What happens when the model refuses to answer? Is that a pass (appropriately cautious) or a fail (unhelpful)? A safety-focused chatbot refusing to answer "how do I pick a lock" is behaving correctly; the same refusal for "how do I change a tire" is a failure. You have to decide upfront and document it in your criteria. This might feel like extra work, but it's work you'd have to do anyway. Binary evaluation makes it visible rather than letting it hide in the ambiguity of a "3."
When writing criteria, start by defining failure rather than success. Ask "what outputs are unacceptable?" and create checks that catch those cases. Describe expected behavior in natural language rather than demanding exact outputs: "the response must mention the refund policy and include a timeframe" works better than pattern matching. Reviewing failures together as a team builds shared understanding and helps refine criteria over time.
The Bottom Line
Binary evaluations might feel less sophisticated than a 1-5 scale. But the goal is useful signal, not sophistication. When you need nuance, reach for more specific criteria, not a wider scale. Five binary questions with explanations will always tell you more than one five-point rating.
This is why we built elluminate around binary yes/no criteria. Every evaluation question is phrased so that "yes" is the positive outcome, and every rating comes with an explanation of why it passed or failed.
If you're spending time debating what "3" means on your evaluation rubric, or struggling to turn LLM scores into concrete improvements, binary evaluations might be worth trying.
The bottom line: binary evaluations force clearer rubrics, produce consistent results whether you're evaluating LLMs or autonomous agents, and give you metrics you can act on immediately.
Frequently Asked Questions
When should I use Likert scales instead of binary evaluations?
Likert scales work well for sentiment analysis, user satisfaction surveys, or preference research: anywhere you're capturing degrees of opinion rather than pass/fail judgments.
How do binary evaluations work for agent evaluation?
The same principles apply. Break agent behavior into specific checkpoints: Did the agent complete the task? Did it use the correct tools? Did it avoid unnecessary steps? Each becomes a binary check.
What if my evaluation rubric needs more nuance?
Decompose it into multiple binary criteria. Five yes/no questions with explanations tell you more than one five-point scale, and you'll know exactly which dimension failed.
We'd be happy to show you how elluminate handles criteria definition, automated evaluation, and result analysis.
Schedule a Demo