AI is moving fast - but trust is lagging behind.
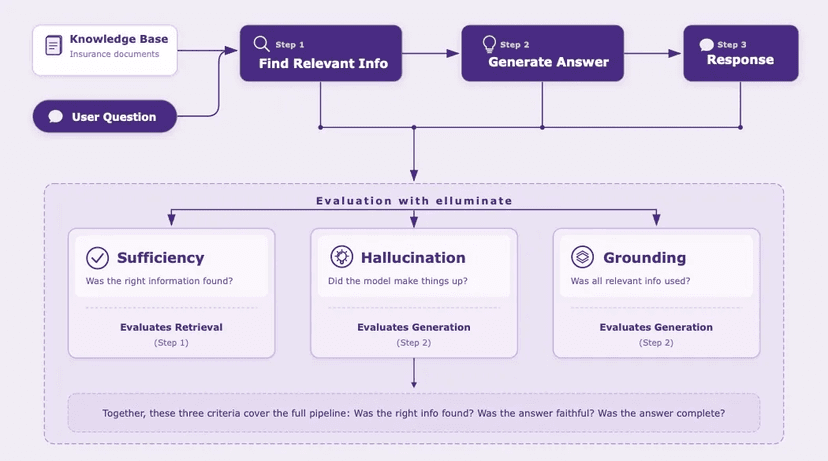
What is elluminate?
That's why we built elluminate.
elluminate transforms evaluation from a chaotic, manual process into a structured system. With elluminate, you can:
- Test prompts systematically before they reach production
- Define clear success criteria and measure performance objectively
- Identify edge cases and failure modes early
- Monitor live applications to catch regressions before users do
The result? Reliable, measurable, and production-ready AI.
Why Evaluation Matters
Most AI teams face the same problem: their models look great in demos but fall apart in production. Why? Because evaluation is done informally — a few spot checks here, some manual reviews there, and lots of "it seems to work."
This guesswork creates three big risks:
- Inconsistency: prompts or models behave differently across use cases, with no way to know why.
- Blind spots: edge cases go undetected until they hit real users.
- Lack of proof: without measurable success criteria, there's no way to defend performance to stakeholders, customers, or regulators.
elluminate solves this by giving you the building blocks of systematic evaluation:
- Prompt Templates: stop copy-pasting and start versioning. Templates make prompts reusable and measurable.
- Collections: test datasets that mix real examples with edge cases, so failures appear early, not in production.
- Criteria: binary, yes/no measures of success. No more "seems good"; every response is objectively scored.
- LLM Configurations: run evaluations with the same model settings you'll use in production, so results reflect reality.
- Experiments: bring it all together: prompts + data + criteria + models = measurable performance.
Step 1: Prompt Templates
The problem: Prompts are written ad-hoc, tweaked endlessly, and quickly lost in version chaos. Teams can't track what worked or why.
The elluminate fix: Prompt templates make this process structured. A template is reusable and versioned. Instead of rewriting the same question over and over, you create a flexible structure with placeholders. Every iteration is tracked automatically, so you never lose the context of what you tested before.
Pizza experiment: Instead of copy-pasting "Does pineapple belong on pizza?" and then "What about mushrooms?" into the playground, you create one template:

That {{ingredient}} placeholder can take any value from your dataset. Now you can test dozens of toppings with consistency, while keeping the output format locked down.
Over time, elluminate shows you how template versions evolve, so iteration becomes easy to track.
Step 2: Collections
The problem: Most teams test prompts with just a few “happy path” examples. That makes outputs look fine in demos, but as soon as a user asks something odd, the system breaks. Without systematic test data, blind spots stay hidden until they reach production.
The elluminate fix: Collections are structured datasets that feed into your templates. They let you mix clean examples, controversial ones, and adversarial “trick” cases so you see both strengths and weaknesses early. Instead of testing only what you expect, you deliberately probe the edges.
Pizza experiment: A solid collection might include:
- Clear fits: mozzarella, pepperoni, mushrooms.
- Controversial cases: pineapple, anchovies.
- Dessert curveballs: chocolate chips, ice cream.
- Non-food adversarials: spoon, plastic, motor oil.
By running your template against this variety, you learn more than “the prompt works.” You learn where it fails, whether it gets confused by cultural toppings, wrongly classifies desserts, or misses obvious inedibles. This practice of including edge cases is what makes elluminate evaluations production-grade.
Step 3: Criteria
The problem: Even with good test data, many teams fall into the trap of subjective evaluation. One reviewer says “good enough,” another disagrees. Or worse: criteria are written so vaguely (“Is the answer correct?”) that nobody can measure them consistently. Without objective metrics, you can't compare runs or know if you're improving.
The elluminate fix: In elluminate, every evaluation criterion is binary — pass or fail. That forces clarity. Instead of best-guess judgments, you define crisp yes/no checks. You can then add “golden answers” to your collections so results are evaluated automatically against your source of truth.
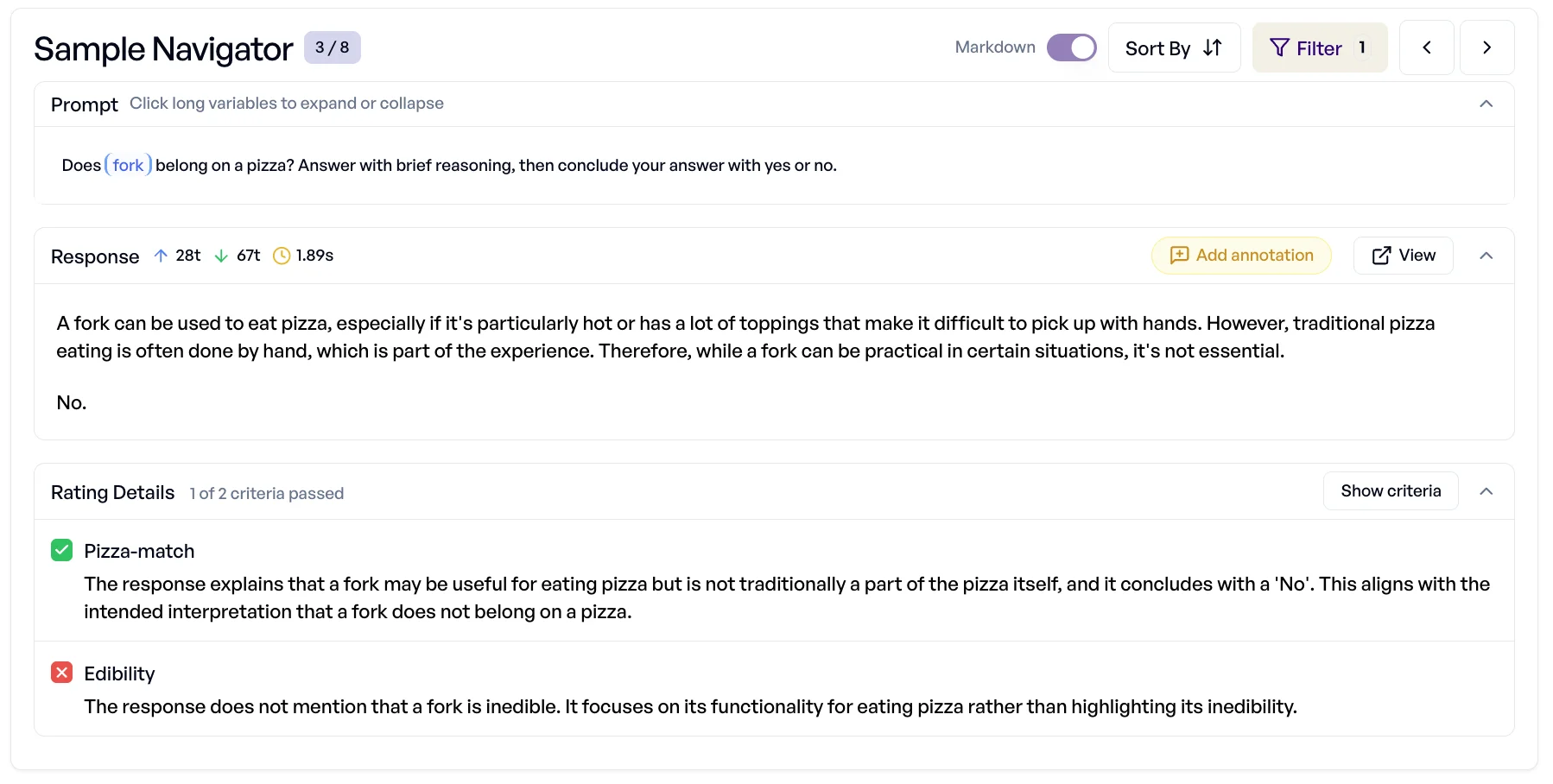
Pizza experiment: Suppose you create one criterion:
"Is the item edible? Does the the topping ingredient belong on pizza?"
That's two questions in one, which makes evaluation messy. A model could correctly say “motor oil doesn't belong on pizza,” but still fail to flag that it's not edible.
The fix is to split criteria:
- Edibility:“Is the ingredient edible?”
- Pizza-matching: “Does the ingredient belong on pizza?”
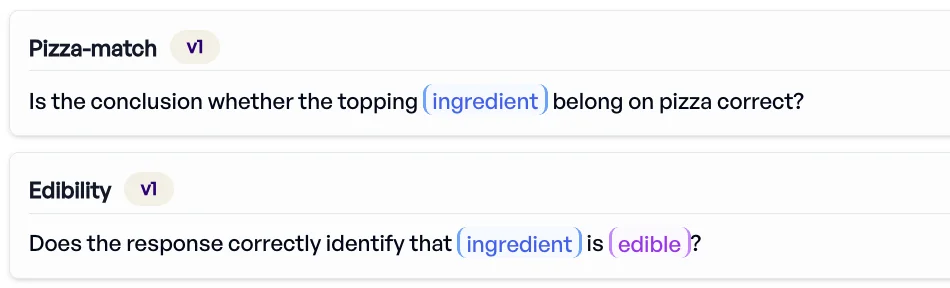
Now you can enrich your collection with labels for edibility (“edible” / “inedible”) and compare model outputs against ground truth. This provides insightful information: you'll know if the issue was with recognizing food safety, omission, or with the cultural understanding about toppings.
Step 4: Choosing the Right Model
The problem: Teams often default to the biggest, most expensive model they can find, assuming “more powerful” equals “better.” But in reality, different models behave differently. Some are fast but shallow, some are nuanced but costly, and others are fine-tuned for very specific tasks. Without a way to compare them, you risk wasting money or deploying the wrong tool for the job.
The elluminate fix: elluminate lets you configure and compare multiple LLMs side by side. You can test small vs. large models, general vs. domain-specialized, and measure how each performs against the same dataset and criteria. Instead of guessing, you see exactly which model works best for your use case.
Pizza example:
- A small, fast model might get 95% of toppings right at a fraction of the cost — perfect for high-volume classification.
- A larger reasoning model might catch subtleties, like saying “ice cream could belong on a dessert pizza,” showing deeper context awareness.
- A specialized model fine-tuned on food data could outperform both, if your domain is narrow.
The point isn't to crown a universal winner, it's to find the right balance of speed, cost, and accuracy for your application. With elluminate, you can prove which model is best, instead of relying on hype.
Step 5: Running Experiments and Interpreting Results
The problem: Raw scores can be misleading. A model that looks good at first glance (say, 90% accuracy) may hide serious blind spots. Without breaking results down, you don't know where it fails, why it fails, or whether those failures matter in production.
The elluminate fix: elluminate doesn't just give you one number. It gives you layers of insight:
- Overall score: a quick headline view of accuracy.
- Criteria performance: see if the model is struggling with “edibility” vs. “pizza-matching.”
- Failure cases: dive into specific examples the model got wrong for each criterion.
- Consistency over runs: compare how stable the model is across repeated experiments or epochs.
Pizza experiment:Your baseline experiment shows:
- 89.5% success overall score
- 93% success on “does it belong on pizza?”
- 86% success on “is it edible?”.
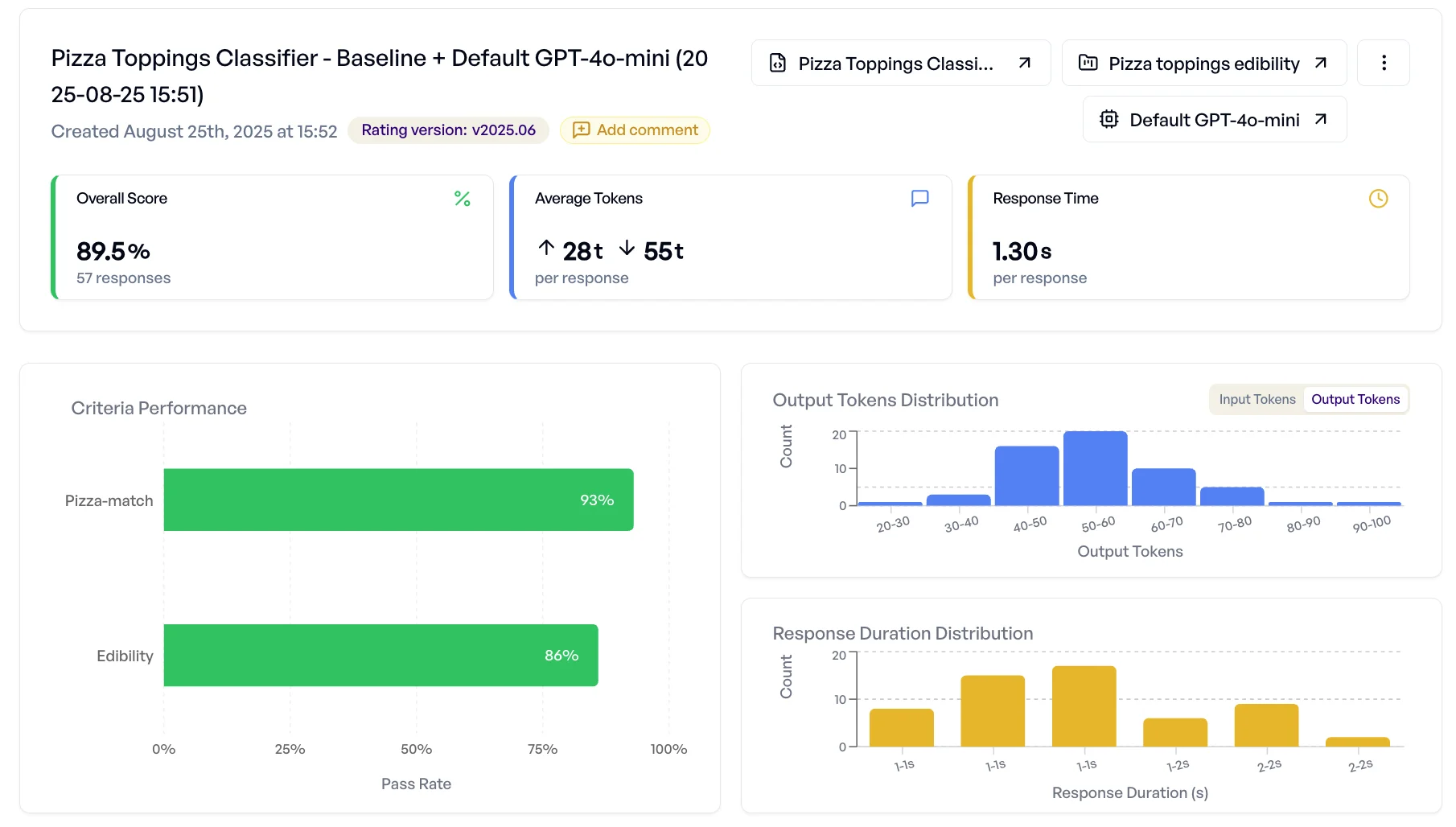
On the surface, 89.5% overall accuracy looks fine. But digging in, you discover the model is misclassifying chocolate chips as “inedible” and sometimes failing to separate utensils from food. Those aren't necessarily random mistakes; they may reveal systematic weaknesses.
By analyzing failures directly in elluminate, you can understand the nuances of wrong responses. That's the difference between anecdotal testing (“it worked for me”) and systematic evaluation (“here's why it fails, and here's how to fix it”).
Step 6: Iteration & Improvement
The elluminate fix: Iteration in elluminate is traceable. Every failed case is logged. Every score tells you whether the problem lies in prompt clarity, model settings, or criteria design. That means improvements are deliberate, not random.
Pizza experiment:
- If format compliance is failing (the model gives essays instead of “Yes/No”), you know to tighten your prompt instructions first.
- If desserts keep getting flagged as inedible, the issue might be your criteria or labels, not the model.
- If results vary wildly on “pepperoni,” your temperature is too high or you model is reasoning in excess.
The key is knowing when you're “good enough.” At 95% accuracy with clear understanding of the remaining 5%, you're ready for production. Perfect is a trap — even humans disagree on whether mayonnaise belongs on pizza.
The Decision Layer for Reliable AI
We've used pizza toppings to show how elluminate works — but the stakes are much higher in real-world AI. For enterprises, the problems are clear:
- Compliance risk: in regulated sectors, you can't ship AI without proving it meets standards.
- Customer experience: one bad response from a chatbot can erode trust instantly.
- Operational cost: testing by hand doesn't scale, and chasing failures wastes weeks.
- Model choice paralysis: without systematic comparisons, you either overpay for big models or gamble with small ones.
elluminate solves these problems by making evaluation repeatable, measurable, and defensible. Whether you're building internal copilots, customer-facing assistants, or automated document workflows, elluminate gives you the confidence that your AI will behave consistently, even under pressure.
The difference is simple: without evaluations, AI is unpredictable. With elluminate, AI becomes reliable, auditable, and production-ready.
And you don't have to figure it out alone. Our founders work directly with early customers to design evaluation strategies tailored to their systems — from prompt iteration to live monitoring.
Book a private demo with our founders and see how elluminate can transform your workflow.
Schedule a Demo with Our Founders